
当下最适合财会人的AI大模型,我们找到了!
当下最适合财会人的AI大模型,我们找到了!
https://mp.weixin.qq.com/s/172JiZcuT2h0OWLeKhNTzg - 微信公众平台
- 当前适合财会人员使用的免费大模型排名
、
- 2024-05-07 09:10:16

作者 | 财务数字化探索团队
编辑 | 沈佳艺 李成智 朱海莹
头图 | DALL·E 3生成
PART1 背景简介

在当下AI大模型千帆竞渡、百舸争流的背景下,如何选择一款满足自身需求的大模型,成为了众多使用者面临的重大难题。
鉴于目前尚无对各AI大模型在财务专业领域表现的综合性评价,本期我们挑选了目前国内外免费的主流大模型, 并基于自主建立的评价体系展开测评,以期选出现阶段最适合财会人员使用的大模型!
PART2 整体测试结果
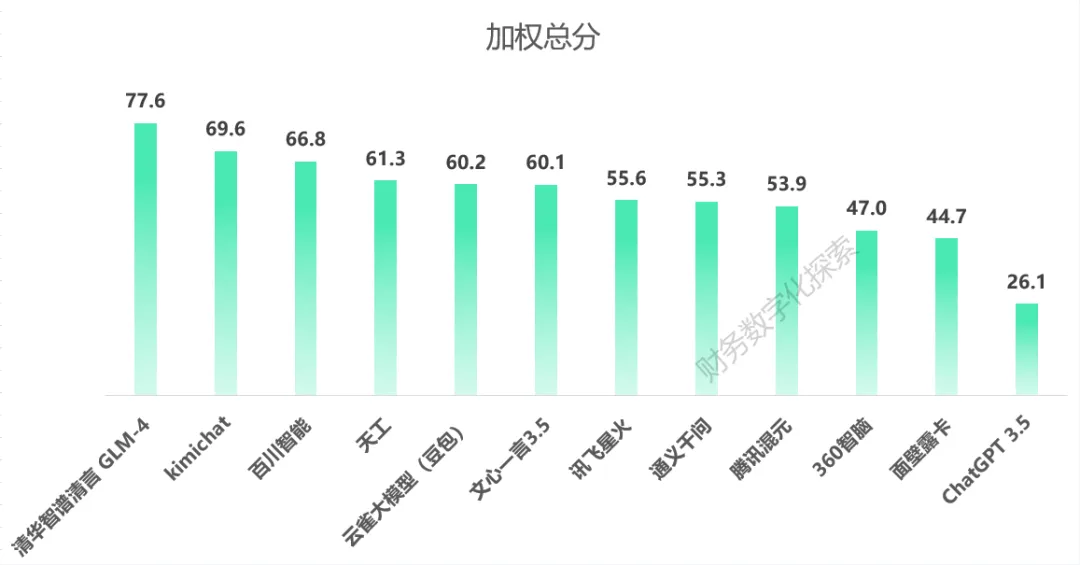
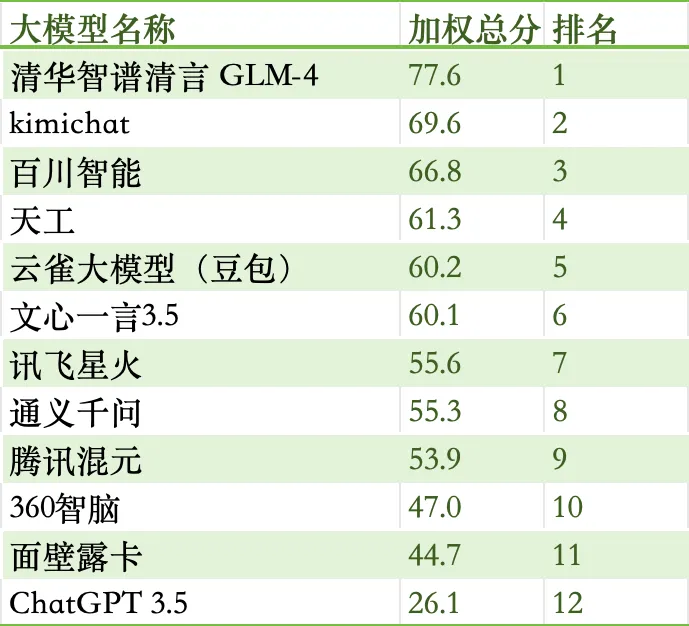
在参与测试的12款大模型产品中,清华智谱清言得分GLM-4得分最高,为77.6分,ChatGPT 3.5得分最低,为26.1分,整体测试结果如下:
PART3 测试方案
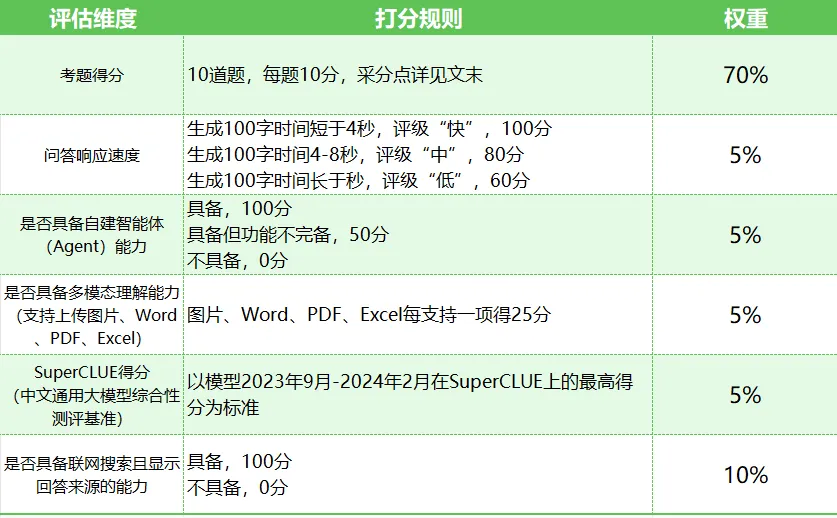
【评估维度】
-
会计主观题考题打分,从 【审计实务】 、 【会计分录】 、 【税法规定】 、 【管理会计】 、 【财务管理】 五个方向一共提出10个CPA难度的会计主观题

-
问答响应速度
-
是否具备自建智能体(Agent)能力
-
是否具备多模态理解能力(支持上传图片、Word、PDF、Excel)
-
是否具备联网搜索且显示回答来源的能力
-
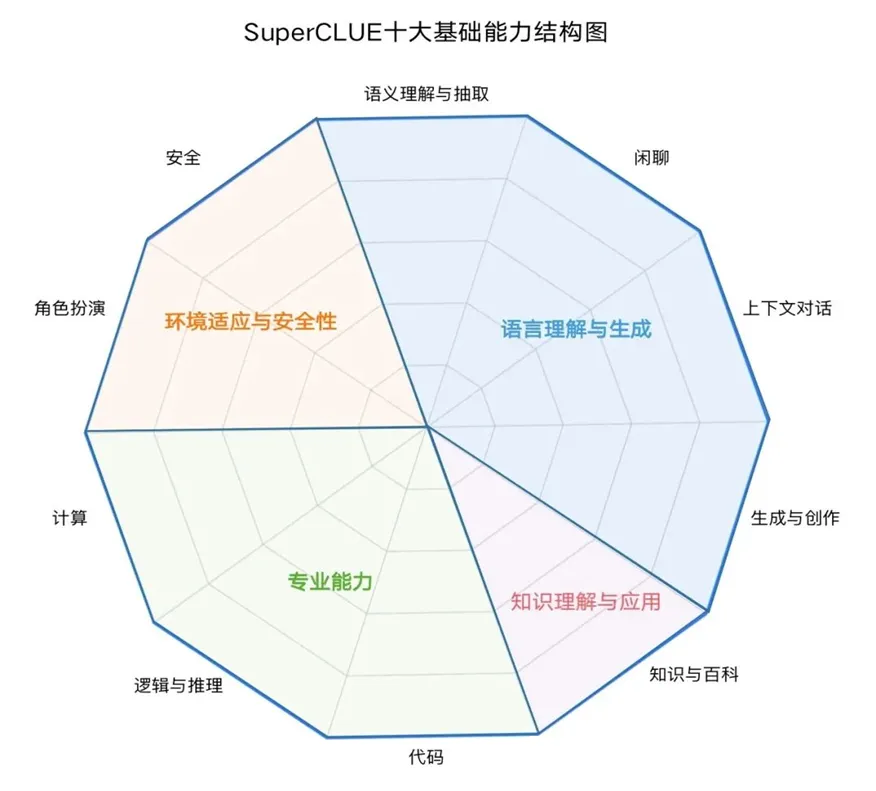
SuperCLUE得分(中文通用大模型综合性测评基准),该基准评估维度包括以下方面:
【测试对象】
ChatGPT 3.5、通义千问、云雀大模型(豆包)、kimichat、百川智能、文心一言3.5、清华智谱清言GLM-4、讯飞星火、360智脑、腾讯混元、面壁露卡、天工(本文所使用的AI大模型均是目前国内外主流免费大模型)

【打分细则】
【统一Prompt提示词设计】
为了提高大模型回答的精确度,我们设计了如下统一提示词:

PART4 各维度测试结果展示
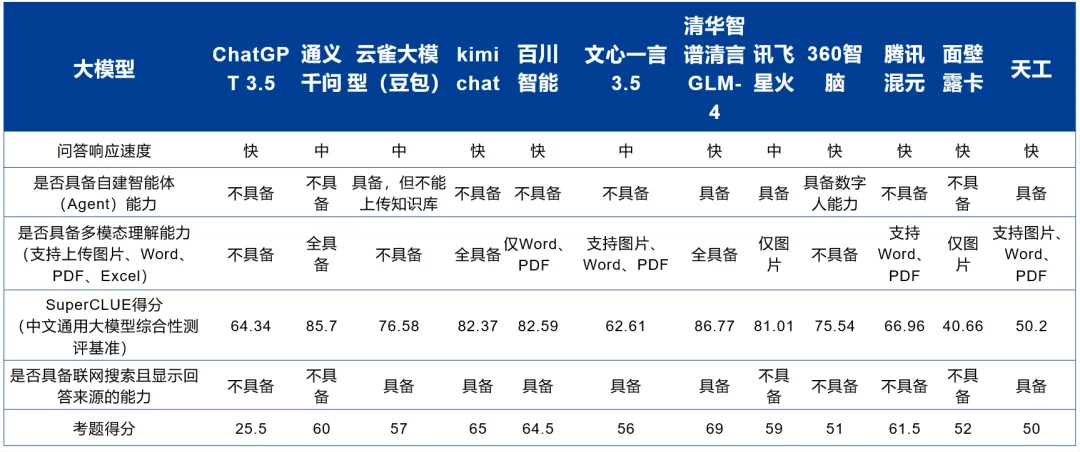
各维度整体回答情况如下表:
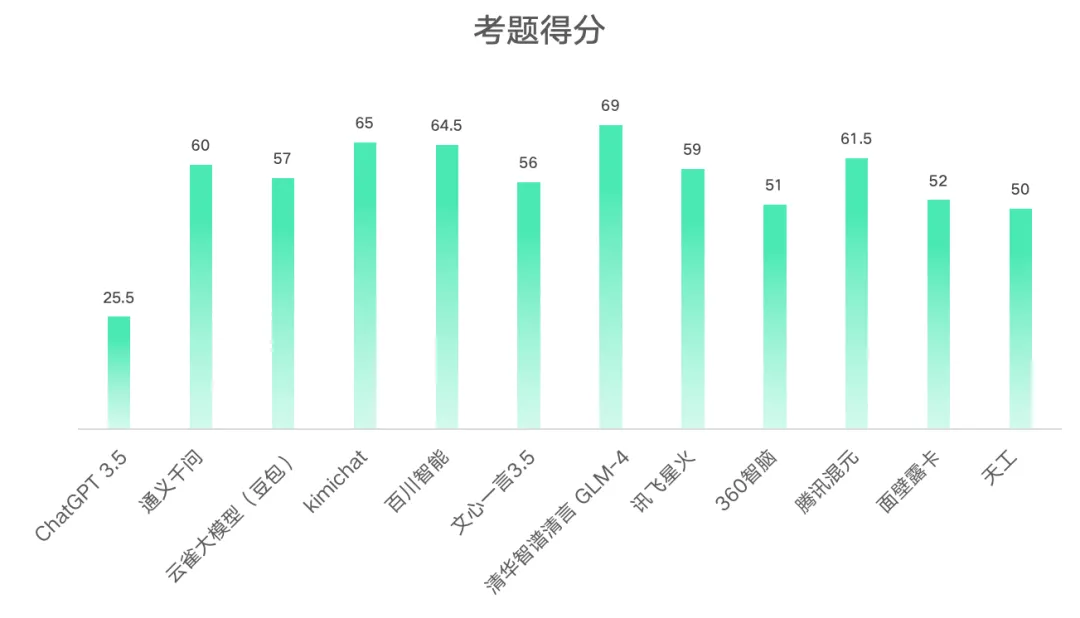
1.会计考题得分情况
从结果可以看出考题得分最佳的是清华智谱清言GLM-4 69分,最差的是ChatGPT3.5 25.5分;所有大模型平均得分为55.875分。
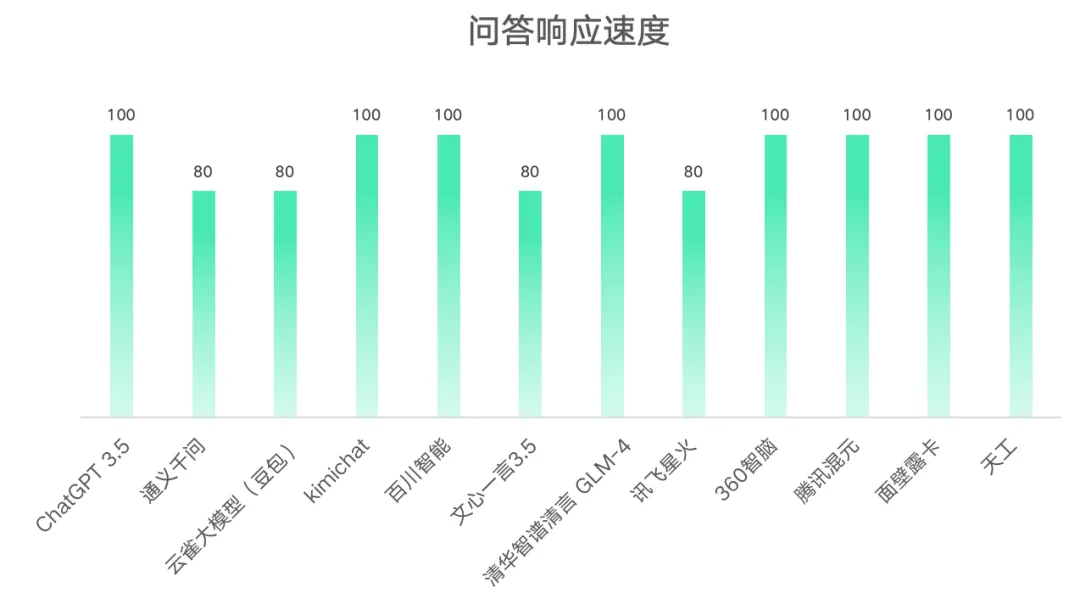
2.问答相应速度得分情况
从结果可以看出在12个大模型中,有8个大模型回答响应速度较快,可以在短语4秒到时间内生成100字;而4个大模型相对较慢,生成100字需要花费4-8秒的时间。
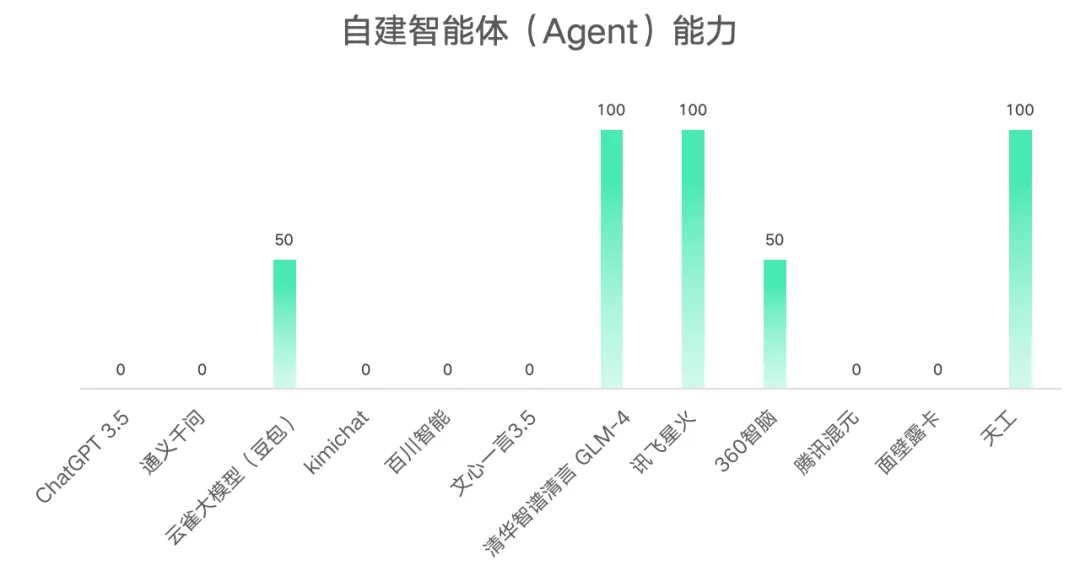
3.自建智能体(Agent)能力得分情况
从结果可以看出仅有清华智谱清言GLM-4、讯飞星火、天工完全具备自建智能体(Agent)能力。云雀大模型(豆包)、360智脑虽然在一定程度上具备自建智能体(Agent)能力,但功能并不完备。其余AI大模型测试发现完全不具备自建智能体(Agent)能力。
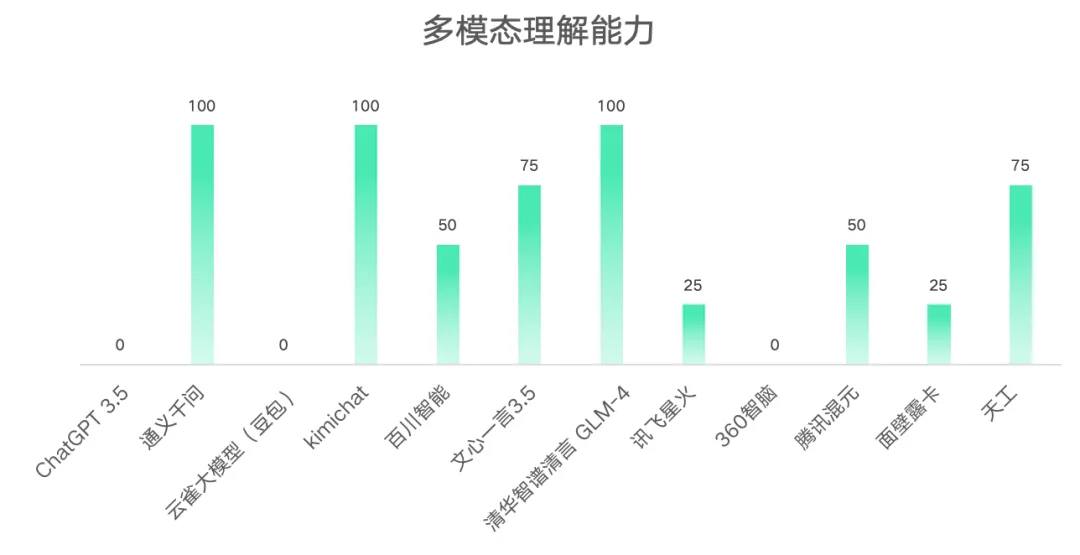
4.多模态理解能力得分情况
从结果可以看出通义千问、kimichat、清华智谱清言GLM-4支持上传图片、Word、PDF、Excel每一种类型的文件。ChatGPT 3.5、云雀大模型(豆包)、360智脑任何形式的文件均不支持上传。其余6种AI大模型支持其中的1-3种文件类型的上传。
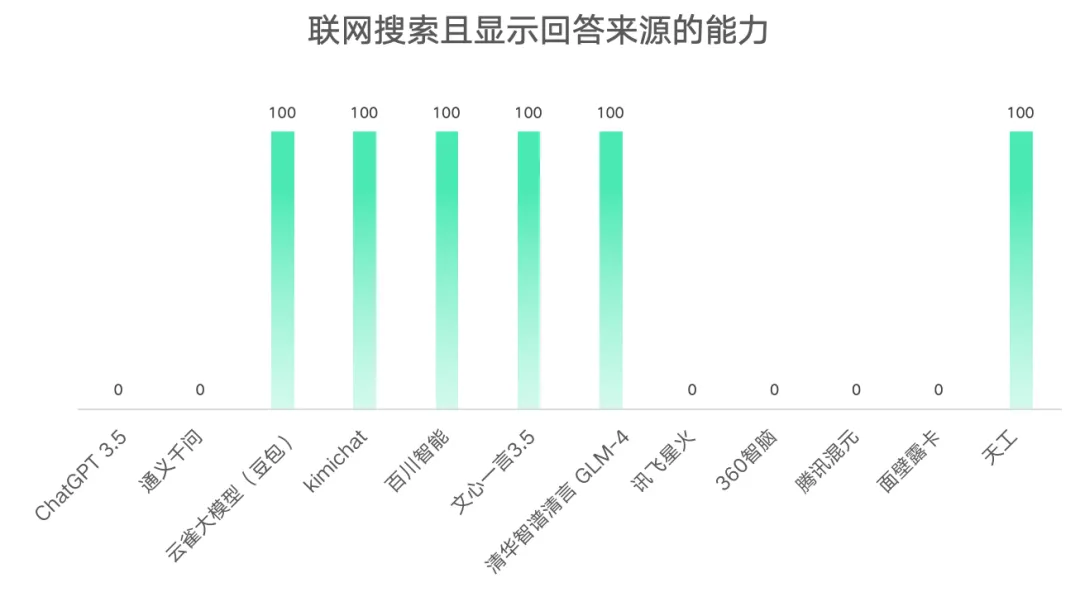
5.联网搜索且显示回答来源的能力得分情况
从结果可以看出云雀大模型(豆包) 、kimichat、百川智能、文心一言3.5、清华智谱清言GLM-4、天工均具备联网搜索且显示回答来源的能力。其余AI大模型均不具备该项能力。
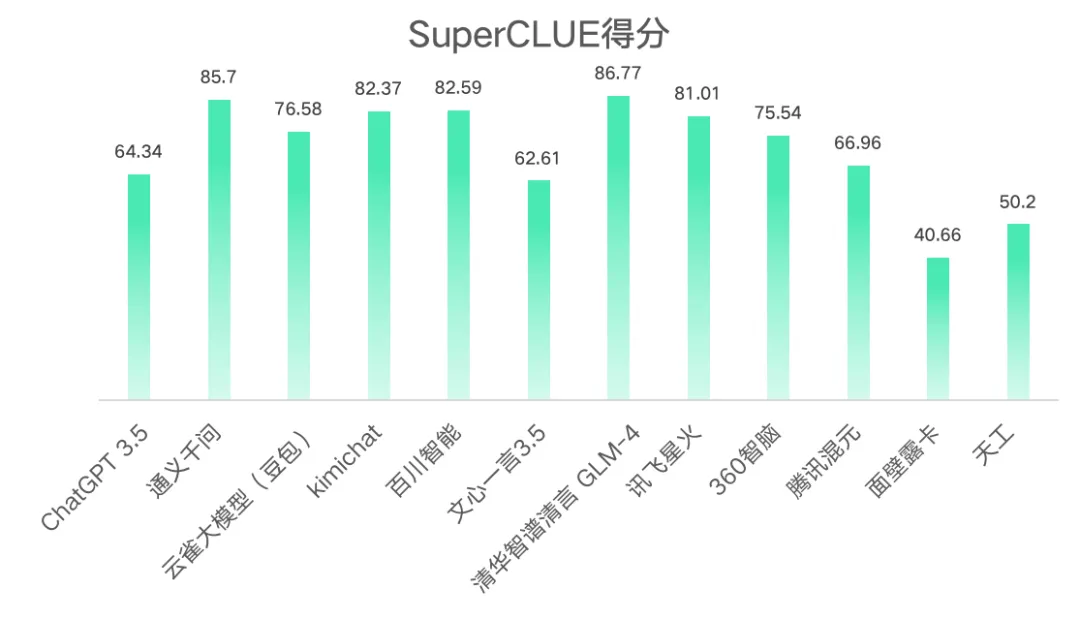
6.SuperCLUE得分情况
从结果可以看出清华智谱清言GLM-4以86.77的高分占据第一,通义千问以85.7的分数位列第二,面壁露卡得分最低,为40.66。
PART5 总结与思考
基于我们的测试结果,当前适合财会人员使用的免费大模型排名如下:
关于本次测试,还有如下几点说明和总结:
1.我们的问题选择、答案打分、评价体系设计都带有一定的主观性,此外由于测试题目数量有限无法全面衡量各大模型的财务能力,所有得出的结论仅是我们的一得之见,结果仅供参考,也相信大模型在后续的更新迭代中会有更好的表现。
2.可以发现ChatGPT分数不算高,可能因为我们的问题均为中国会计准则相关,由于国产大模型本土化水平较高,因此表现较好,而ChatGPT则在中文语境下回答质量欠佳;此外,由于目前ChatGPT仅有3.5版本免费,我们没有将能力更强的GPT-4纳入测试范围。
3.问题中有几道计算题模型给出了正确的公式,但是计算准确度不高,代入数字之后产生了错误,这可能说明大模型本身还是语言模型,在不调用代码能力的情况下,在计算上有所欠缺。比如ChatGPT就犯了如下计算错误。

4.智谱清言得分较高的一大原因是在部分主观题中,其依托联网能力直接在相关准则中检索到了正确答案。如下图,智谱清言直接给出了参考的准则链接。

5.目前大模型的会计分录生成能力普遍较差,较我们一年前测试时改善并不明显《我们给ChatGPT出了五道会计题》,记录科目不准确、借贷不平、基本只会一借一贷的现象仍普遍存在。
6.为了保证测试结果能让广大财务同仁看得见、用得上,我们仅选用了当前免费版本的大模型产品参与测试,性能更好的付费版例如文心一言4.0,GPT-4并不在此次测试的范围内。

在这个AI大模型“百模大战”的时代,我们见证了科技的飞速发展,同时也感受到了财务人员在时代浪潮中的困惑与迷茫。
我们希望通过这次评测,降低信息不对称,让大模型的便利触达更多财务人的工作,帮助财务人员在这场科技盛宴中找到属于自己的“利器”,提升财务工作的幸福感。我们诚挚地邀请大家一起分享、传播这次评测的结果,让更多的行业同仁受益!
本测试中使用的免费国内大模型链接
智谱清言 https://chatglm.cn/
讯飞星火 https://xinghuo.xfyun.cn/
腾讯混元 https://hunyuan.tencent.com/
面壁露卡 ************https://luca.cn/chat
360智脑 https://chat.360.com/?
KimiChat https://kimi.moonshot.cn/
通义千问 https://tongyi.aliyun.com/qianwen/
云雀大模型(豆包) https://www.doubao.com/chat
百川智能 https://www.baichuan-ai.com/home
后台回复“大模型测试”,获取测试全部详细回答Excel文件
在这里,一起做财务数字化世界的
同行者、见证者和探索者
欢迎关注
