
RAGFlow 本地部署及 Dify 调用,让你的本地大模型更有深度(保证好使)
RAGFlow 本地部署及 Dify 调用,让你的本地大模型更有深度(保证好使)
- https://blog.csdn.net/zjw529507929/article/details/146585530
- 文章浏览阅读3.2k次,点赞37次,收藏58次。在人工智能飞速发展的今天,大模型的应用越来越广泛。然而,许多人在使用大模型时面临着各种限制,例如数据隐私问题、高昂的云服务费用等。本地部署大模型并结合有效的工具来提升其性能成为了一种极具吸引力的解决方案。本文将为大家详细介绍如何通过 RAGFlow 进行本地部署,并利用 Dify 进行调用,让你的本地大模型发挥出更强大的能力,为各种应用场景提供有力支持。_dify调用ragflow
- 2025-08-11 09:03:16
RAGFlow 本地部署及 Dify 调用,让你的本地大模型更有深度(保证好使)
简介
在人工智能飞速发展的今天,大模型的应用越来越广泛。然而,许多人在使用大模型时面临着各种限制,例如数据隐私问题、高昂的云服务费用等。本地部署大模型并结合有效的工具来提升其性能成为了一种极具吸引力的解决方案。本文将为大家详细介绍如何通过 RAGFlow 进行本地部署,并利用 Dify 进行调用,让你的本地大模型发挥出更强大的能力,为各种应用场景提供有力支持。
RAGFlow 介绍
一、隐私与安全
肯定会有人提出疑问,为什么我们要大费周章的去进行本地部署呢?那既需要硬件的支持,还需要对服务进行维护。这是因为我们有着绝对的隐私和数据保护以及个性化知识库构建的需求。
假设我们希望大模型能根据你们企业的规章制度来回答问题,那么我们肯定需要将这些规章制度或者模型作为附件上传,那么还是会面临以下问题:
一是隐私与数据保护问题。我们联网使用大模型,我们所上传的所有数据必然会上传到服务器上,假如我们上传的是公开文件那还没什么所谓,但是如果是一些内部文件,或者是绝密文件,那数据的隐私性和数据的安全性就无法得到很好的保障了;
二是限制问题。在联网使用大模型时,供应商没可能让你无限制的使用,一般来说都会对你与服务器的交互设置一些限制以保障其服务的稳定性和安全性,例如上传文件就会限制上传文件的数量,以及限制解析时的算力大小,即使是付费用户也是会对你进行限制,如果你想上传的是几百个文件(专业领域的知识库),那联网使用的大模型也是无力支持的;
三是上传文件附件方式使用起来繁琐。仅仅只是将文件作为附件加入对话上下文,每一次想要让模型根据这些附件回答问题的时候,都需要重新上传附件;想要新增、删除、修改已有的附件,同样也是很难实现的。
面对这些需求我们可以通过本地部署对话大模型(如 DeepSeek)来解决隐私和数据保护的需求;通过使用使用 RAG 技术(Retrieval-Augmented Generation,检索增强生成)构建个人知识库来解决个性化知识库构建的需求。
二、RAGFlow 与 RAG 技术
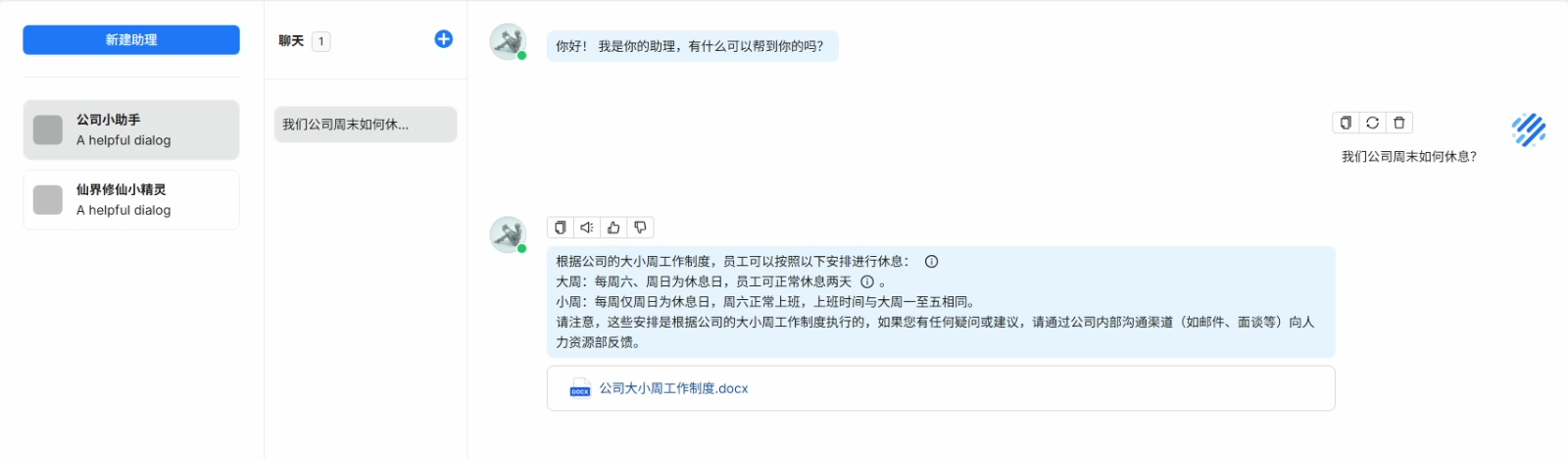
有这么一个情况,你去到一个新公司,你想了解一下这家公司周末是如何休息的,你去问了一下 AI 公司周末是否双休,它会根据很泛的情况进行回复,但是实际上公司实行大小周的,如下图所示

那我们为了解决这种不够个性化的回答,我们就需要使用 RAG 技术来搭建我们个性化的知识库,而本地部署 RAG 技术所需要的开源框架 RAGFlow。
RAGFlow:
其是一个基于检索增强生成(Retrieval-Augmented Generation,RAG)技术的开源框架。RAG 技术的核心思想是在生成文本时,不仅依赖模型自身的知识,还通过检索相关的外部信息来增强生成结果的准确性和丰富性。RAGFlow 将这一技术进行了系统化的封装,使得开发者能够更加便捷地构建基于 RAG 的应用。
RAG 技术原理:
- 检索(Retrieval):当用户提出问题时,系统会从外部的知识库中检索出与用户输入相关的内容
- 增强(Augmentation):系统将检索到的信息与用户的输入结合,扩展模型的上下文。这让生成模型(如 Deepseek)可以利用外部知识,使生成的答案更准确和丰富
- 生成(Generation):生成模型基于增强后的输入生成最终的回答。它结合用户输入和检索到的信息,生成符合逻辑、准确且可读的文本内容
微调技术和RAG技术的区别:
- 微调技术:在已有的预训练模型基础上,再结合特定任务的数据集进一步对其进行训练,使得模型在这一领域中表现更好(微调是考前复习,模型通过训练,消化吸收了这些知识然后给你回复)
- RAG 技术:在生成回答之前,通过信息检索从外部知识库中查找与问题相关的知识,增强生成过程中的信息来源,从而提升生成的质量和准确性。(RAG 是开卷考试,模型看到你的问题,开始翻你的知识库,以实时生成更准确的答案)
三、Embedding
Embedding 通常指的是 Embedding 模型,它与 Chat 大模型(如 Deepseek)最大的不同就是它输出的并不是文本,而是问题的嵌入向量,这有利于知识检索的执行。
在进行检索前需要做一些准备,包括提前的知识储备(外部知识库)和知识库的预处理,分别如下:
- 外部知识库:外部知识库可能来自本地的文件、搜索引擎结果、API 等等。这样,RAG 不仅依赖于模型本身的内在的、通过训练得到的知识,还能实时调用外部的信息进行补充。而在企业规章制度的场景当中我们要构建的就是一个基于本地文件的外部知识库
- 通过 embedding 模型,对知识库文件进行解析:文本是由自然语言组成的,这种格式不利于机器直接计算相似度。embedding 模型要做的,就是将自然语言转化为高维向量,然后通过向量来捕捉到单词或句子背后的语义信息。例如,“周末”“休息”“深度学习”三个词,embedding 模型会将“周末”和“休息”映射到相近的向量空间中;而“深度学习”会被映射到离他们较远的向量空间中,这样通过 embeding 模型的解析,机器就可以学习到自然语言之间的深度语义关系,并且依此计算出不同文本之间的相似关系


当我们通过自然语言给大模型提问题时,系统会从外部的知识库中检索出与用户输入相关的内容,过程如下:
- 通过 embedding 模型,对用户的提问进行处理:用户的输入同样会经过嵌入(Embedding)处理,生成一个高维向量,为的是更好的让用户提问与知识库中的知识做匹配
- 拿用户的提问去匹配本地知识库:使用这个用户输入生成的这个高纬向量,去查询知识库中有无相关的文档片段。系统会利用某些相似度度量(如余弦相似度)去判断这个相似度。这一整个过程可以理解为,上传并解析了知识库之后,相当于给知识库中每一个小的文段都生成了一个指纹;然后用户输入问题之后,这个问题同样也会生成一个独一无二的指纹,接着 RAGFlow 系统就会拿着用户输入的这个指纹,在指纹库也就是知识库中匹配,找到相似的指纹,然后把将检索到的这些相关文段与用户的输入结合,扩展模型的上下文,再喂给 Chat 模型(如 DeepSeek)

RAGFlow 的部署
一、前期准备
环境要求:
- 硬件要求:CPU ≥ 4 cores (x86);内存 ≥ 16 GB;硬盘 ≥ 50 GB
- 软件要求:Ubuntu ≥ 22.04;Docker ≥ 24.0.0 & Docker Compose ≥ v2.26.1 或 Docker Desktop 4.39.0 & Docker Engine 28.0.1(Windows 环境下)
网络要求:
- 本地网络:部署时可以使用 VMware 的 NAT 模式,如果只是本机使用就已经无需调整了,如果是需要内网中为其他设备提供服务,那就需要配置成 bridge(桥接)模式了;如果使用 Docker Desktop 进行部署,只需要保持默认设置即可
- 外部网络: RAGFlow 是使用 docker 进行部署,在构建时需要从网络上拉去镜像,国内虽然有镜像源,但是并没有外面的全,所以可能会导致超时导致构建失败,所以提前准备一个靠谱的“科学上网”是非常必要的
Ollama 的安装:https://blog.csdn.net/zjw529507929/article/details/145768786
docker 的安装:
- Linux 环境:https://blog.csdn.net/qq_75277260/article/details/140246580
- Windows 环境(有图形化界面):https://blog.csdn.net/zjw529507929/article/details/146218875
二、部署步骤
本次演示将会在 Windows 环境下进行安装,Windows 和 Linux 除了 docker 的安装不太一样之外,后面的一系列命令都是一样的。
1、检查系统的网络环境
在装好 Docker Desktop 后开始检查的及时网络问题了,首先我们要把之前提到的 “科学上网” 打开,并调节到全局模式(拉取镜像的成败关键)
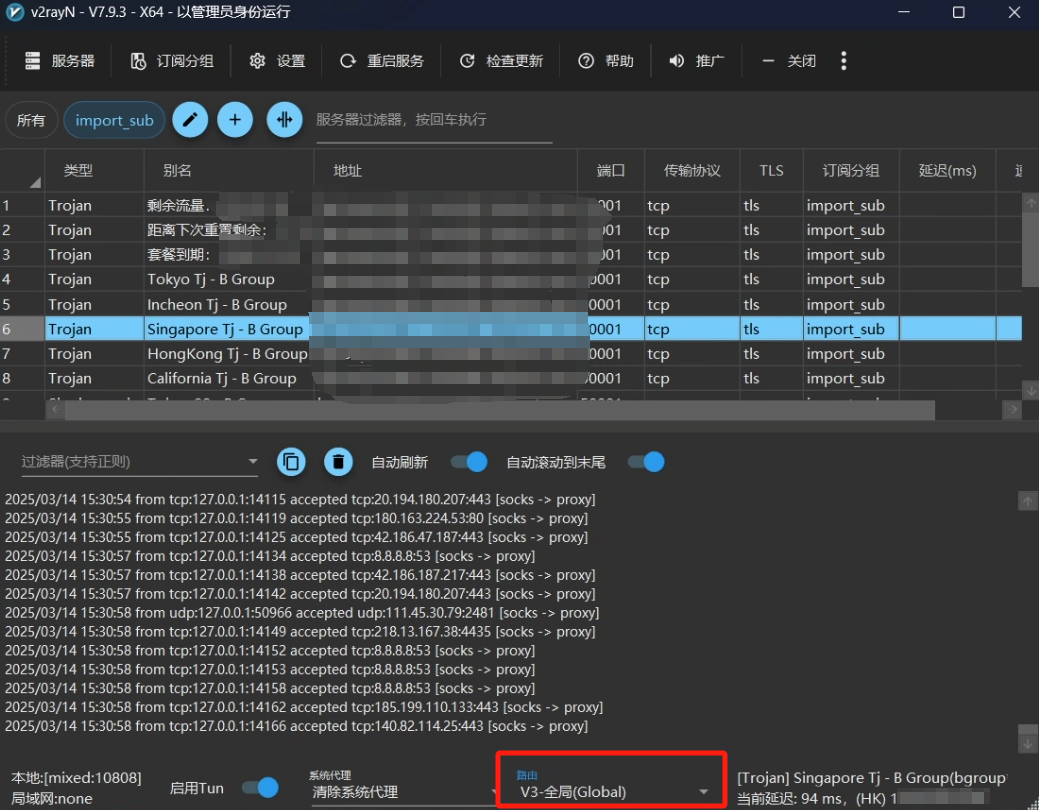
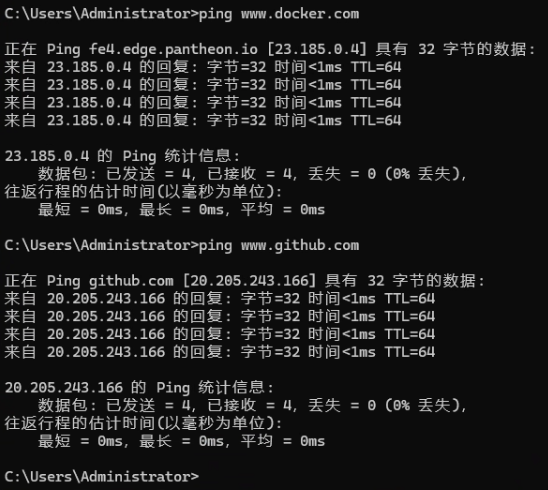
同时即使开了 “科学上网” 有的还是会失败,这是由于运营商的问题,因为每个运营商对于不同 IP 访问的路由设置都不一样,目前在广东测试发现电信是最好使的。可以根据下面的命令进行 ping 测一下:
<p>ping www.docker.com</p>
<p>ping www.github.com</p>
<p>bash
如果到最后实在是没办法了,可以拿我提前安装好的镜像直接导入到 docker 当中来使用,这样就可以避免网络问题了,链接在“备份与加载 RAGFlow 的镜像”的部分。
2、下载 RAGFlow 源码
RAGFlow 是一个开源软件,我们可以直接上 Github 上搜索并下载其源码,链接为:https://github.com/infiniflow/ragflow,可以直接下载 ZIP 压缩包或通过 git 命令下载(需要提前安装 git)
git 的安装:
Linux:
sudo apt-get install -y git
<p>bash
如果已经安装过会如下图所示
Windows:
直接打开该链接下载:Git - Downloads
下载完成后双击安装,安装选项默认即可。然后我们去 Github 上获取克隆链接,如下图所示
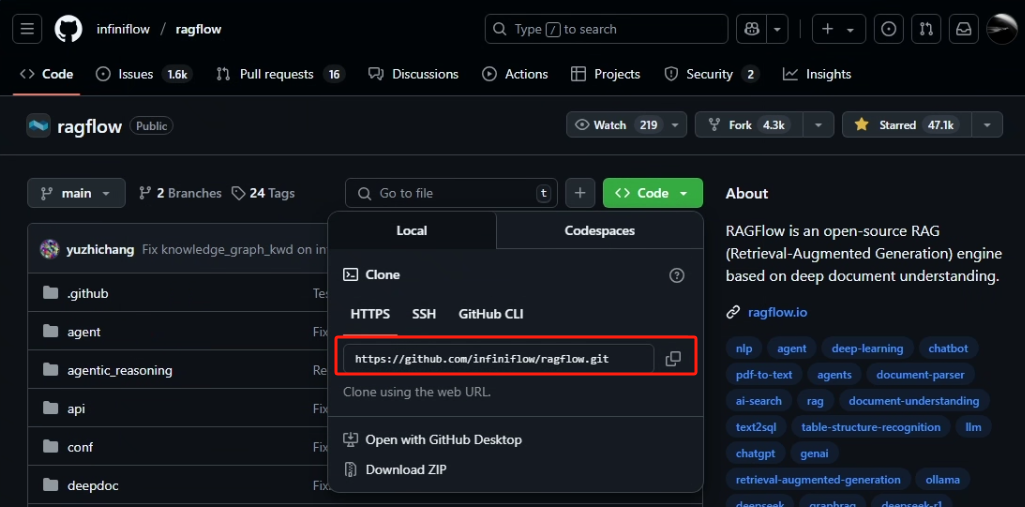
打开目标目录,在地址栏输入 cmd 根据当前目录打开终端,并输入以下命令(该命令会下载到当前所在目录下)
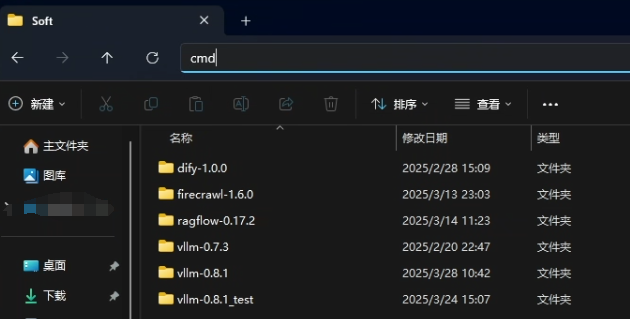
git clone https://github.com/infiniflow/ragflow.git
<p>bash
环境变量与配置文件的修改">3、RAGFlow 环境变量与配置文件的修改
RAGFlow 的源码当中有一个 docker 的目录,这个目录里面有 docker 的环境变量和配置文件
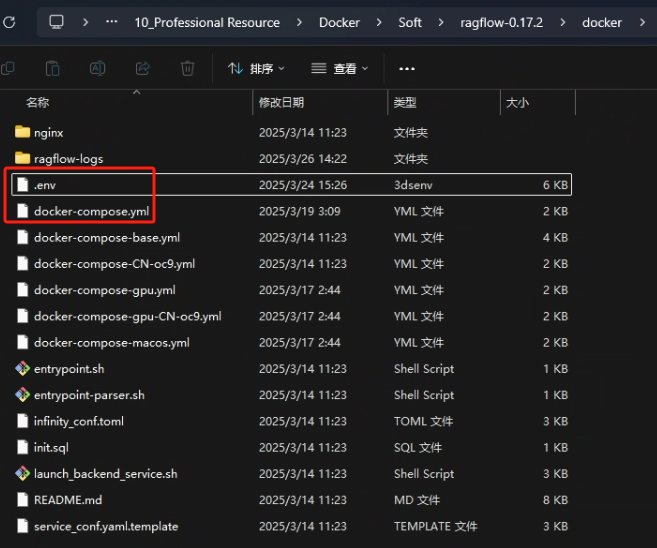
这里我们需要修改两个文件,分别是 .env 和 docker-compose.yaml。
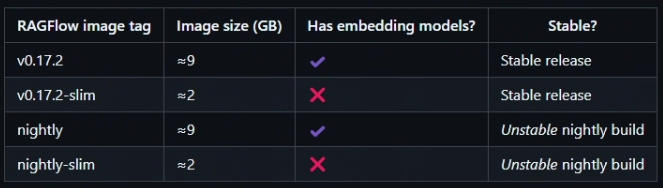
.env:该文件就是该 RAGFlow 的环境变量,默认下载的 RAGFlow 是 slim 版(不带 embedding 模型的版本),我们需要下载 full 版(带 embedding 模型的版本),需要修改的地方如下图所示
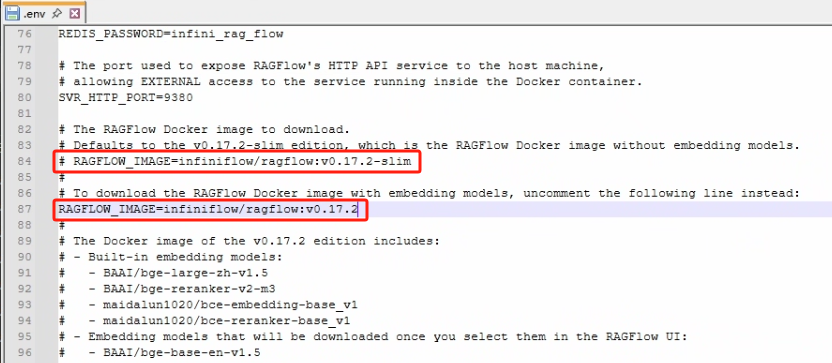
默认 RAGFLOW_IMAGE=infiniflow/ragflow:v0.17.2 是被注释掉的,我们需要去掉该注释,并把原来的 RAGFLOW_IMAGE=infiniflow/ragflow:v0.17.2-slim 注释掉,这样在拉取 docker 镜像时就会拉取 full 版的了
提示:
如果你遇到 Docker 镜像拉不下来的问题,可以在 .env 文件内根据变量 RAGFLOW_IMAGE 的注释提示选择华为云或者阿里云的相应镜像。
华为云镜像名:swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow
阿里云镜像名:registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow
RAGFLOW_IMAGE = swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:v0.17.2
<p>bash
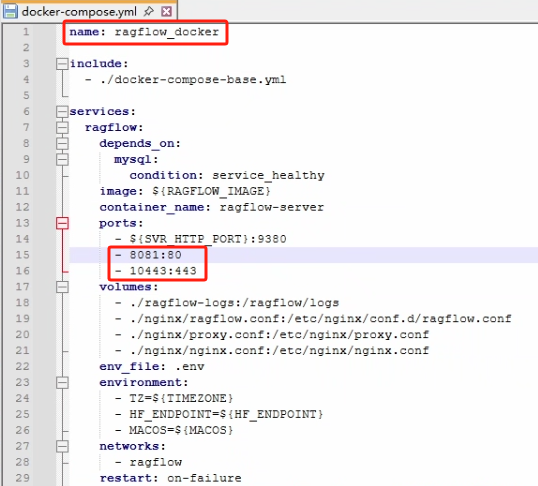
docker-compose.yml:该文件就是该 RAGFlow 的 docker 配置文件了,它继承于 docker-compose-base.yml,docker-compose.yml 只包含了 ragflow-server 容器的配置,其他容器需要在 docker-compose-base.yml 里进行修改。
由于我们后面是想在同一台宿主机上同时使用 Dify 对 RAGFlow 进行调用的,比较坑的是 Dify 和 RAGFlow 的 docker 内部网络默认都是叫 docker,它们内部都使用了 redis(只在 docker 内部网络使用,并没有映射到宿主机当中,在同一个 docker 内部网络才会冲突),并且都使用了 80 和 443 这两个端口,所以我们就需要对 docker 内部网络名进行修改,并且修改 docker 映射到宿主机的端口号,主要修改的是 docker-compose-base.yml 文件,修改如下图所示
4、RAGFlow 构建
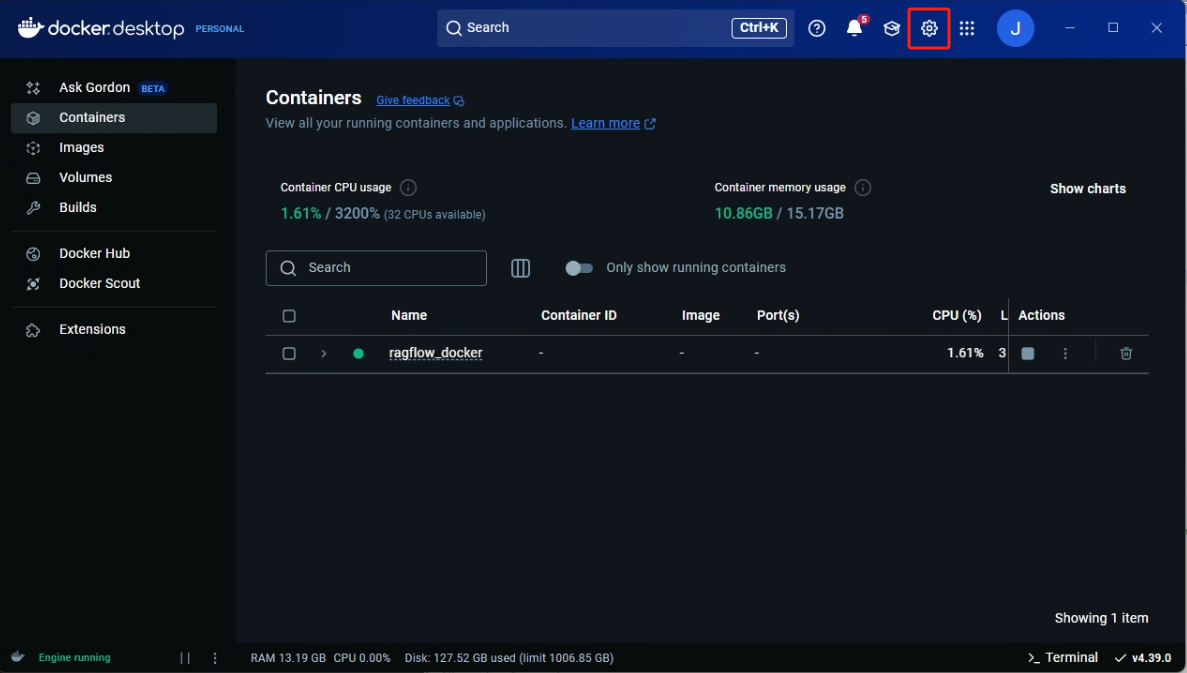
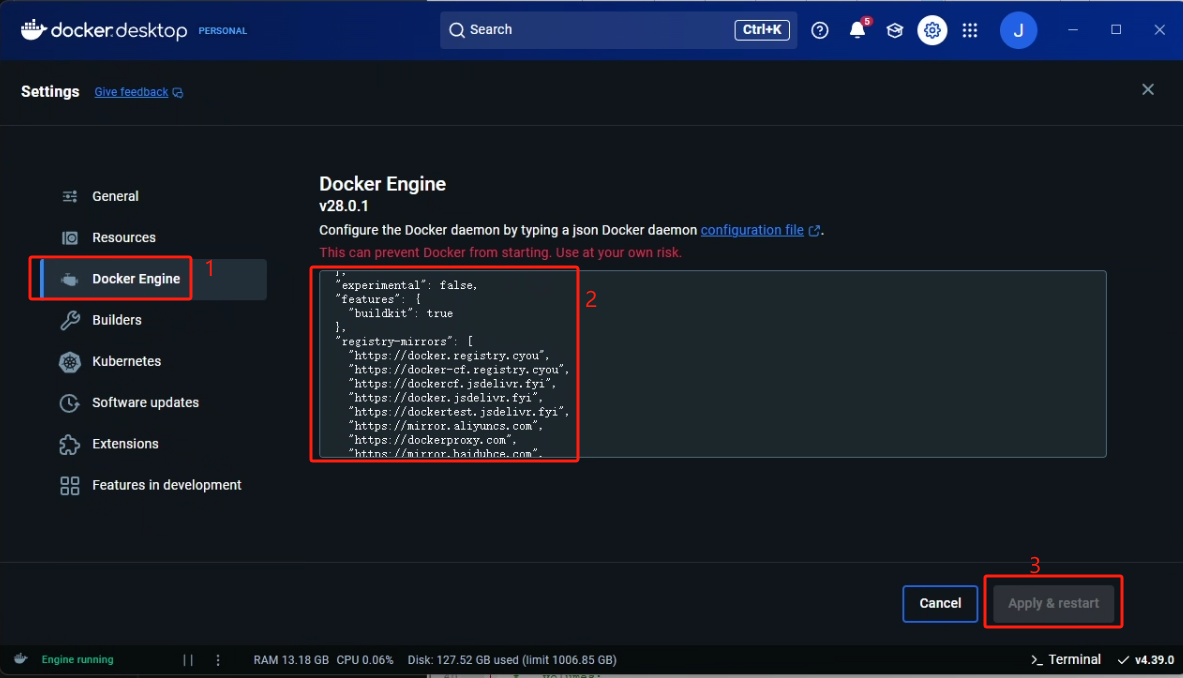
至此正式开始对 RAGFlow docker 的构建,此前我们可以通过国内的镜像源来下载一些依赖镜像,以提高构建的成功率
镜像加速(如果在安装 Docker 的时候已经执行过了请忽略) :
构建 RAGFlow:
注意:构建命令的执行一定要在 docker-compose.yml 文件所在目录下执行
docker compose build
<p>bash
5、RAGFlow 运行
<h1 id="如果是直接导入镜像则不需要重新构建,只需要执行以下命令直接启动就好了">如果是直接导入镜像则不需要重新构建,只需要执行以下命令直接启动就好了</h1>
<p>docker compose up -d</p>
<p>bash
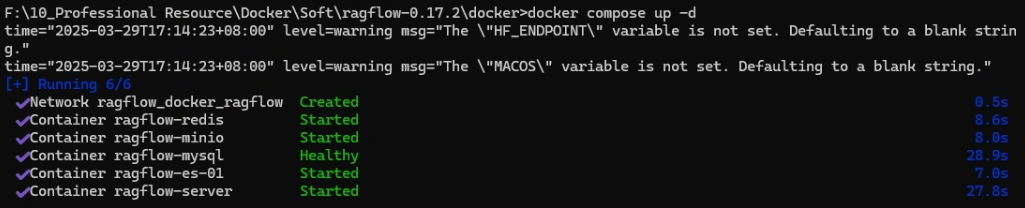
构建完成后看到日志出现下图的标志代表启动成功
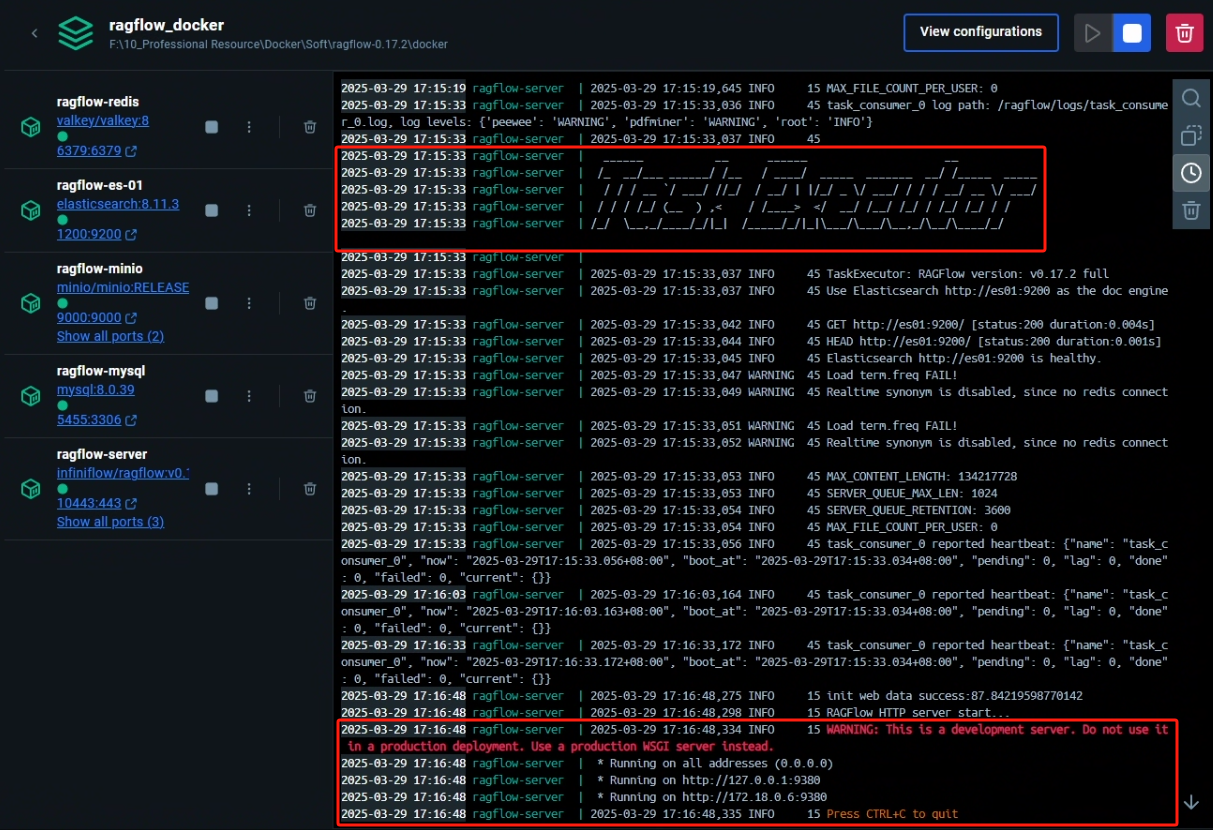
启动完成后在浏览器输入以下 URL 来进行测试
http://127.0.0.1:8081 # 如果没有修改过配置则为 80 端口
<p>bash
我们需要先注册一个账号,然后在进行登录
登陆后需要先去设置我们的模型提供商

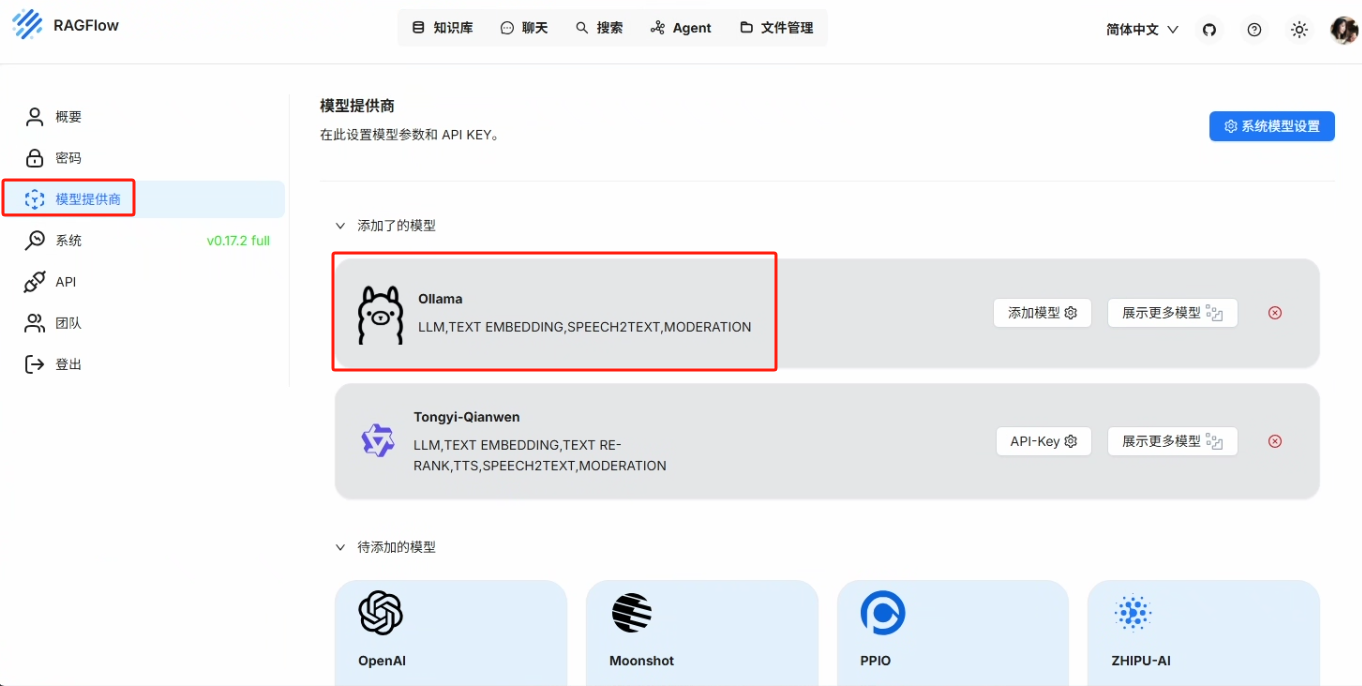
在待添加的模型中选择 Ollama
在基础 Url 中的 IP 地址是需要填当前宿主机网卡上的 IP 地址的,可以通过在命令行当中输入以下命令查看
ipconfig
<p>bash
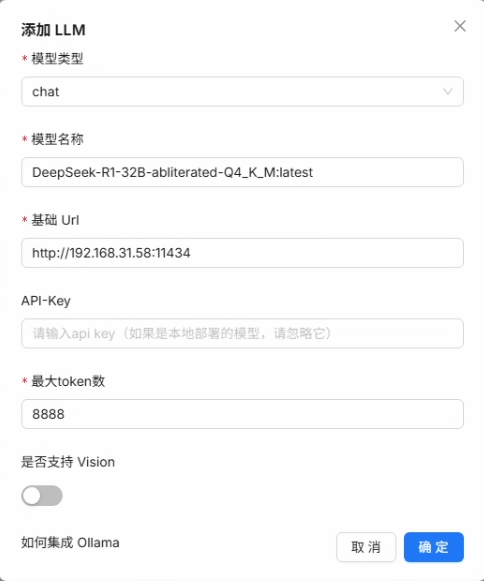
点击确定,添加成功后可以看到在添加了的模型中出现 Ollama,即添加的模型名
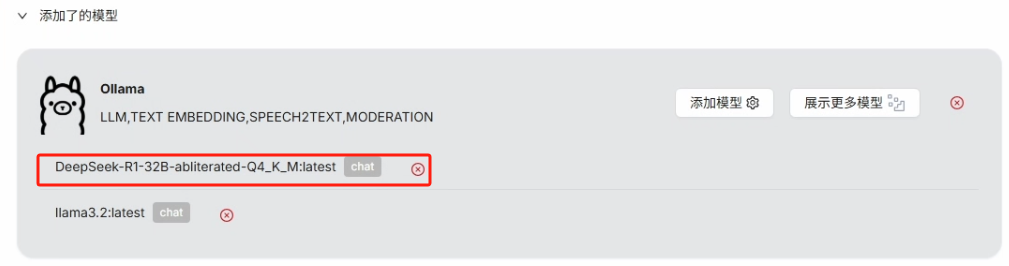
最后需要在系统模型设置当中进行设置
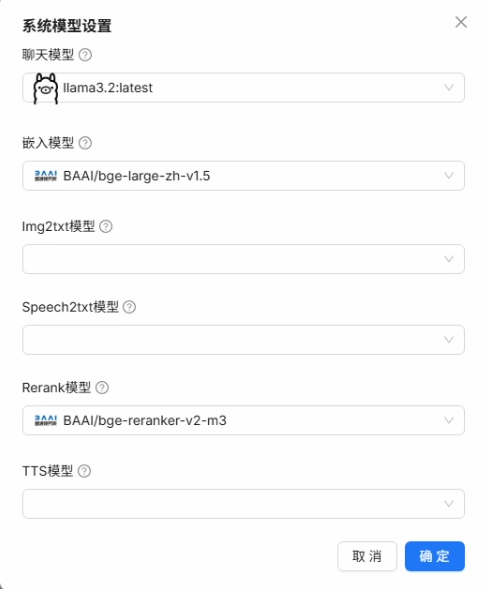
点击确定,至此 RAGFlow 的模型设置就完成了。
6、知识库的创建


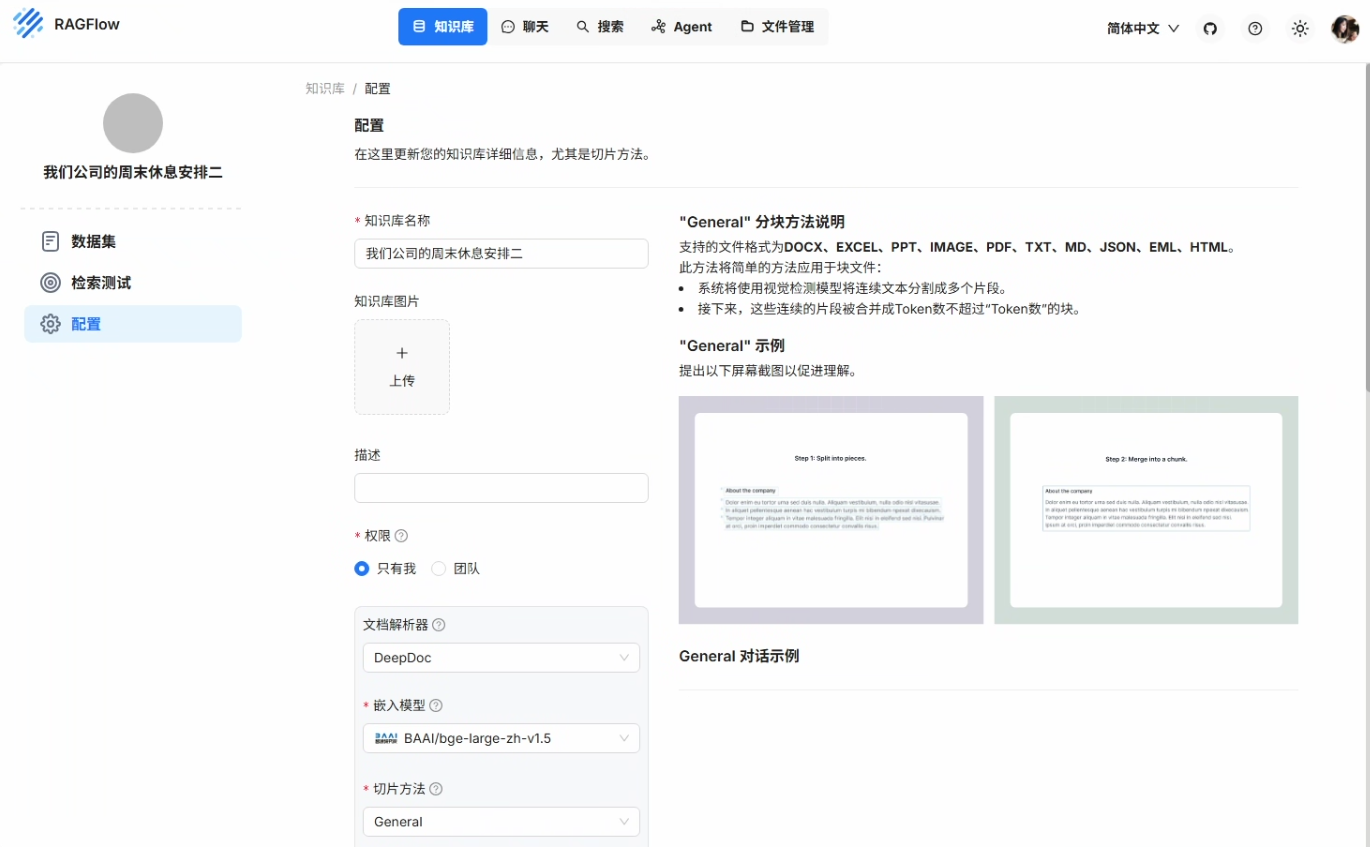 知识库的配置有几个需要注意的点,一个是嵌入模型,默认会使用系统模型设置当中的设置,这里的 zh 代表的是中文,large 代表的是大量会比 samll 性能会更好
知识库的配置有几个需要注意的点,一个是嵌入模型,默认会使用系统模型设置当中的设置,这里的 zh 代表的是中文,large 代表的是大量会比 samll 性能会更好
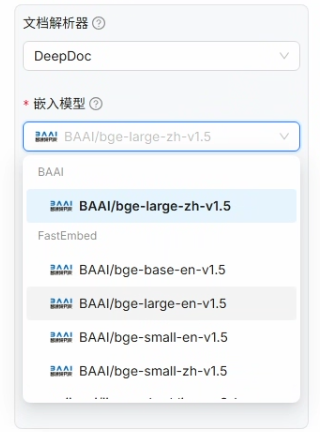
切片方法如果没有特殊要求选 General(通用)就足够了,除此之外还有 Laws(法律条文)、Book(书籍)、Paper(论文)等的切片方法供选择
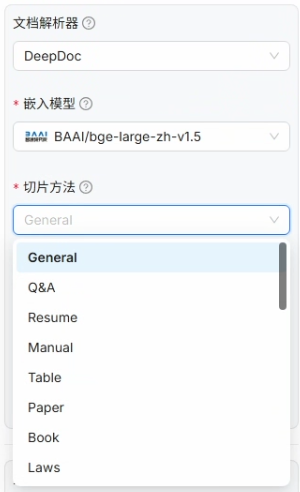
其他的配置保持默认,保存即可,到此你的知识库就创建完毕了
7、文件的上传与解析
知识库建立完成后我们就可以开始上传我们的文件来创建知识库的数据集了,上传操作如下所示
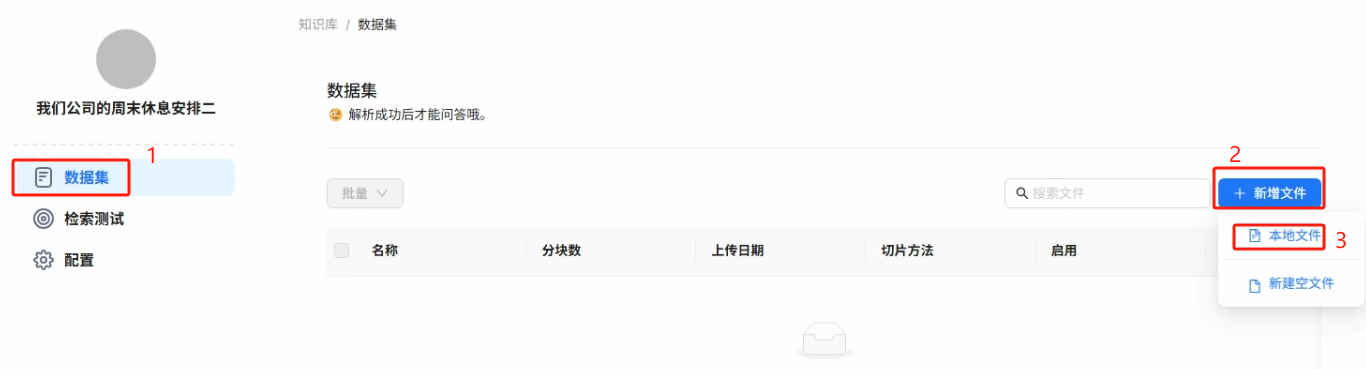
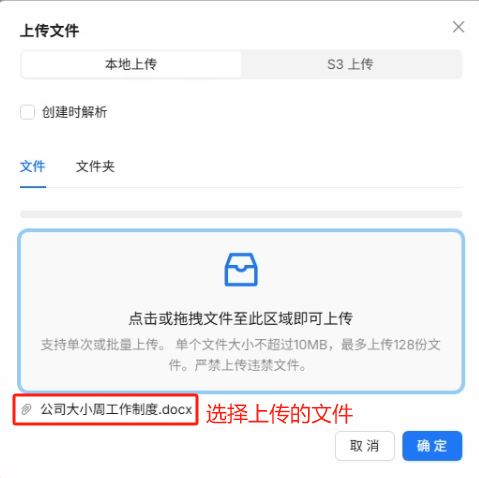
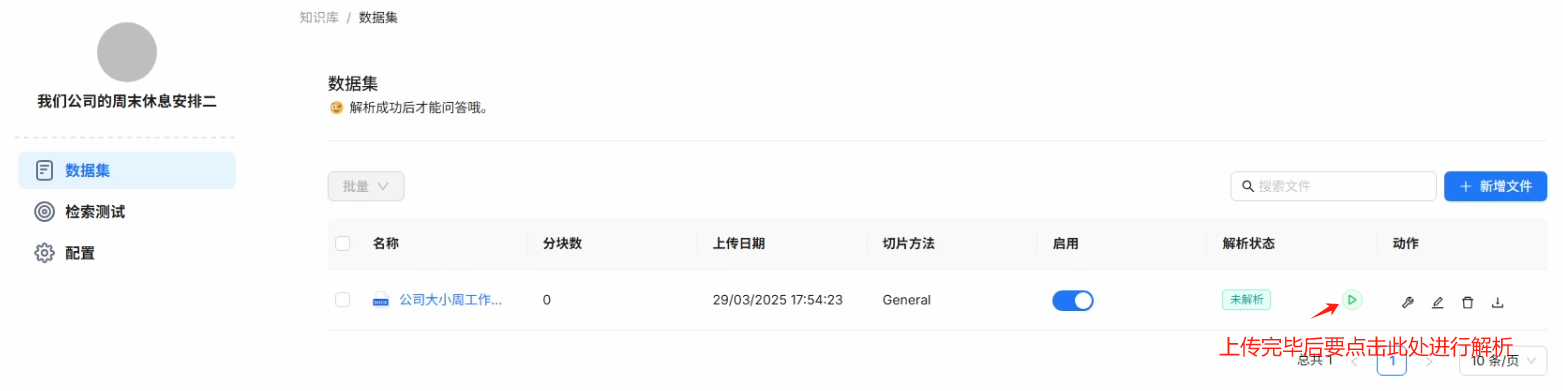 注意:上传文件后一定要点击解析,否则大模型是无法理解你文件当中的自然语言的
注意:上传文件后一定要点击解析,否则大模型是无法理解你文件当中的自然语言的


解析成功后可以到聊天当中进行测试

我们新建助理来指定我们刚刚创建的知识库

我们在创建助理时,可以让助理关联多个知识库成为公司百事通,也可以只让该助理专门回答关于周末休息的知识,当然一个专员和一个泛员回答同一个问题肯定是专员效果更好一点的
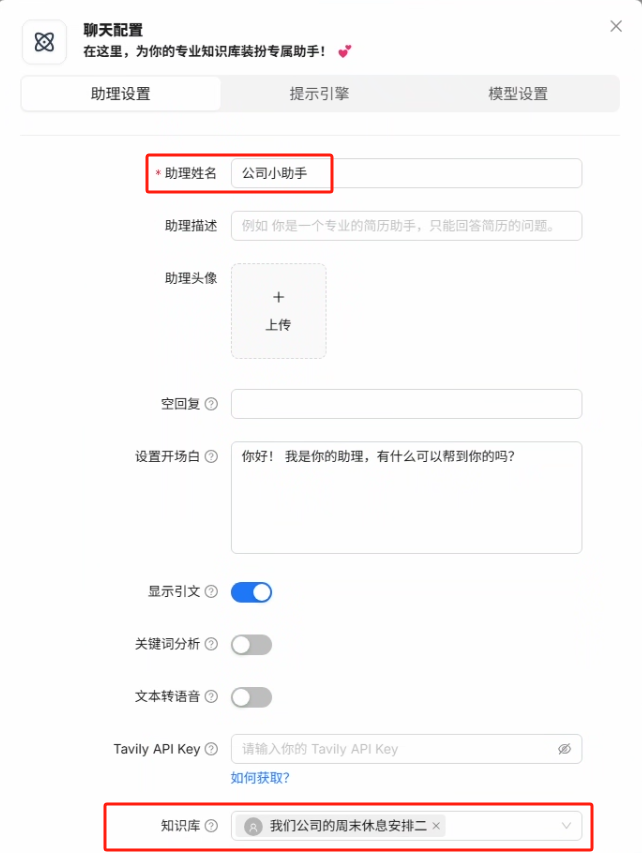
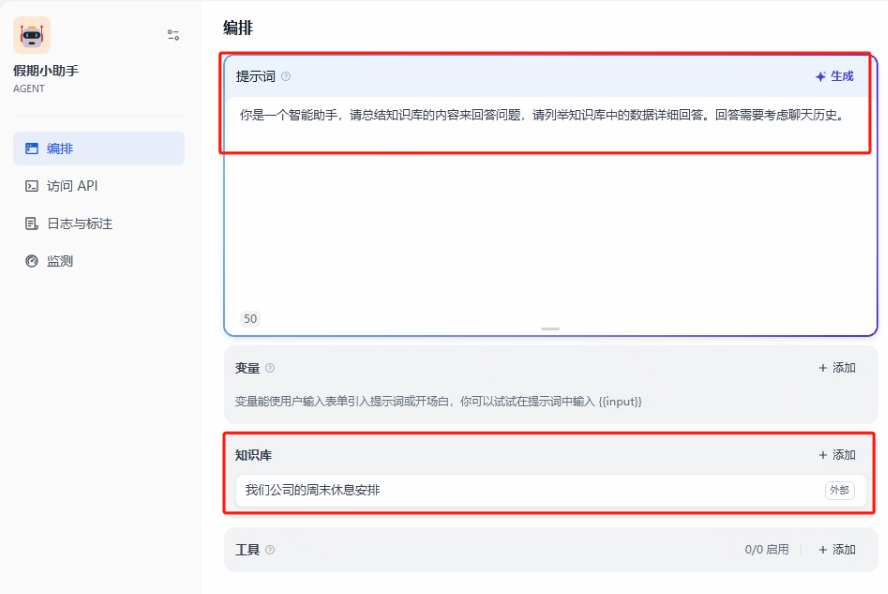
助理默认的提示词中如果没有找到相关提示词的话会直接回答没有相关的答案,如果不想要这种结果,可以把红框中的这句话删除,这样 AI 在知识库找到相关内容时就会按照自己的方式来进行回答了
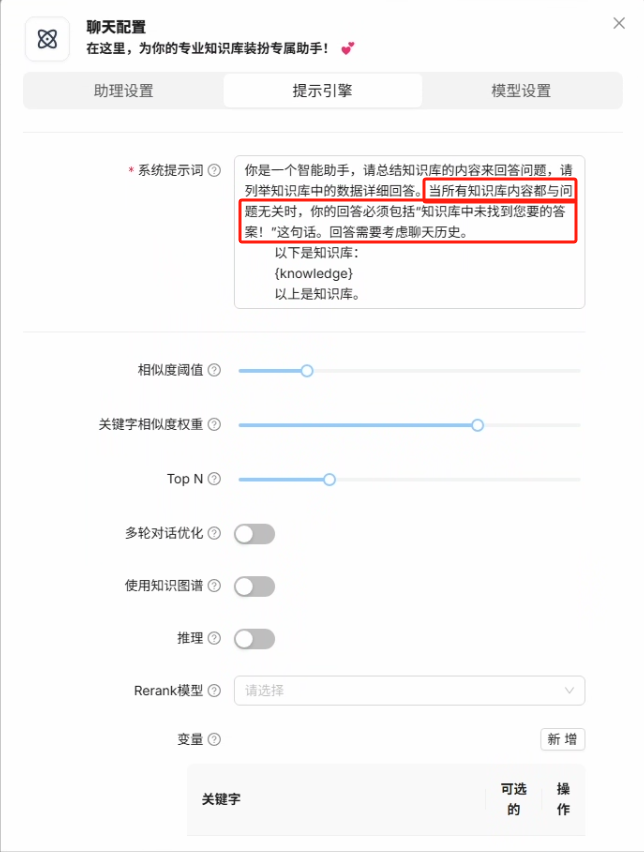
在模型设置当中默认会使用系统模型设置当中的设置,也可以设置当前助理的回答的自由度参数(对于一些制度的查询感觉没有深度思考的大模型会比较准确)
最后我们点击加号新建聊天就可以开始对话了
Dify 的调用
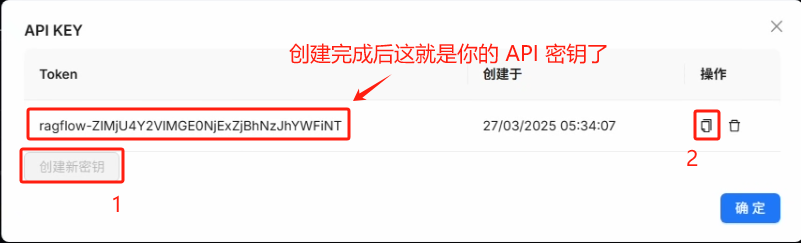
1、在 RAGFlow 中创建 API Key
2、在部署好的 Dify(v1.0.0)当进行外部知识库的设置

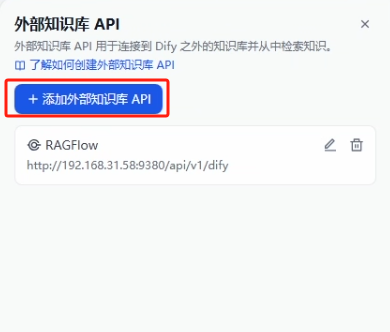
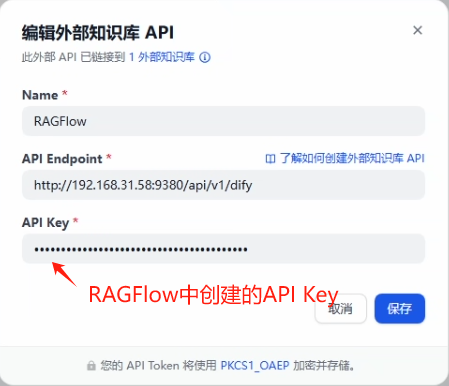
这里的 API Endpoint 的 IP 地址一定是要宿主机网卡上的 IP 地址,不要用 127.0.0.1 或 localhost
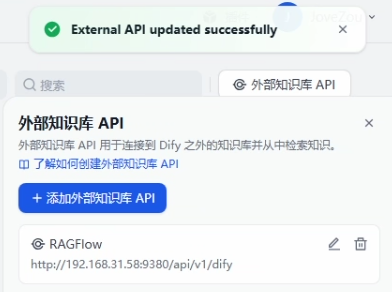
3、创建外部知识库
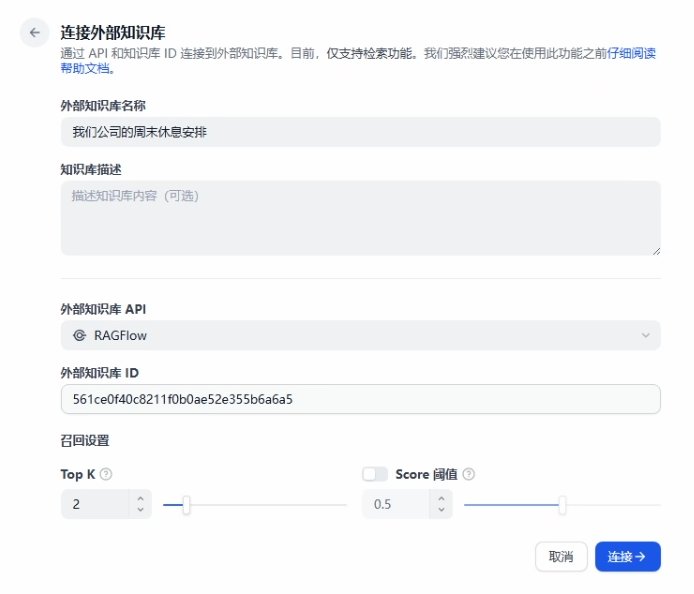
知识库 ID 可以在 URL 当中找到
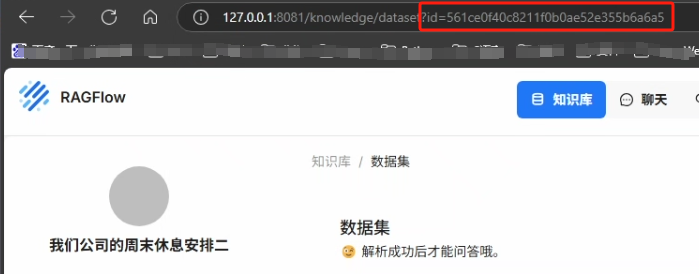
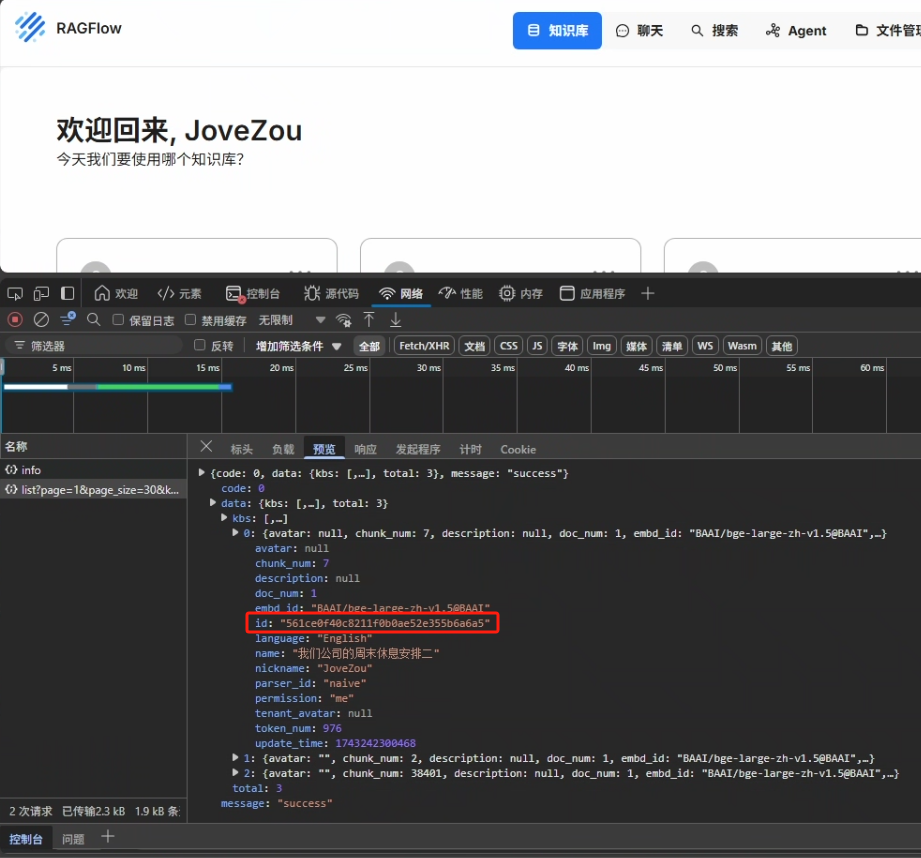
也可以在浏览器中按 F12 中的网络包找到,如下图所示
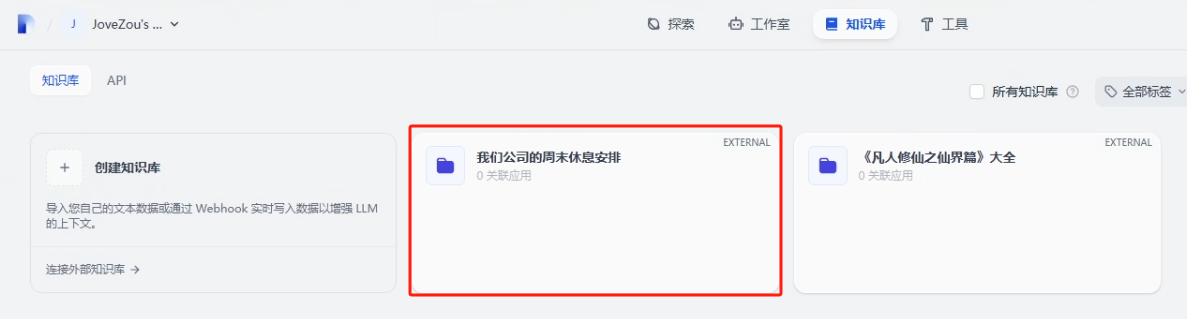
创建成功就可以在知识库当中看到了
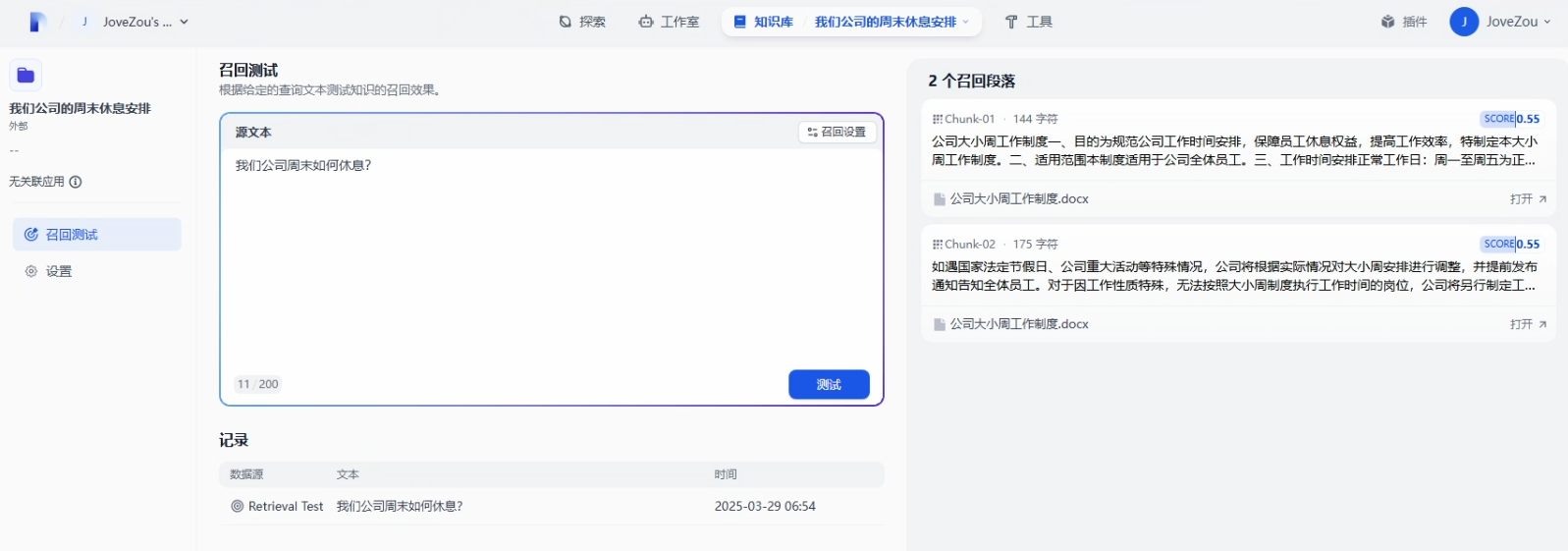
点击进入,我们可以对外部知识库进行召回测试,看看是否能成功调用
4、测试
创建了一个 Agent 应用来对外部知识库进行测试
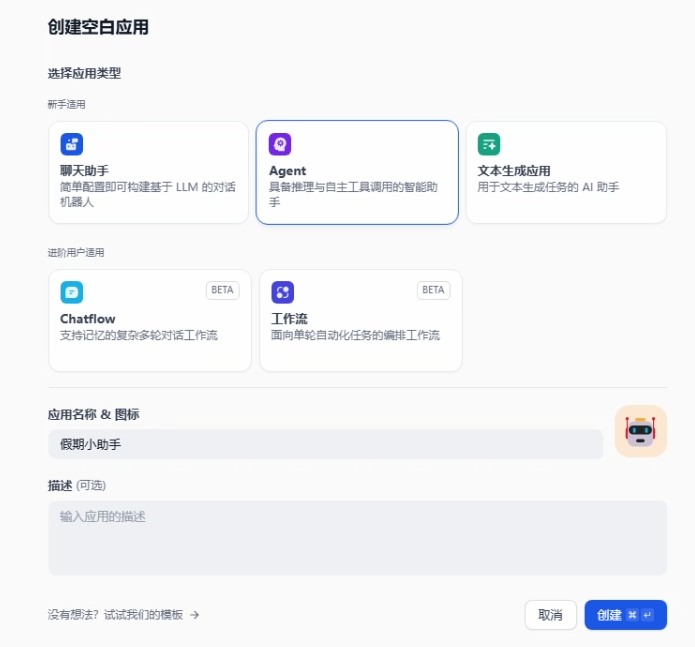
设置外部知识库,与 RAGFlow 中一样,我们可以添加多个知识库
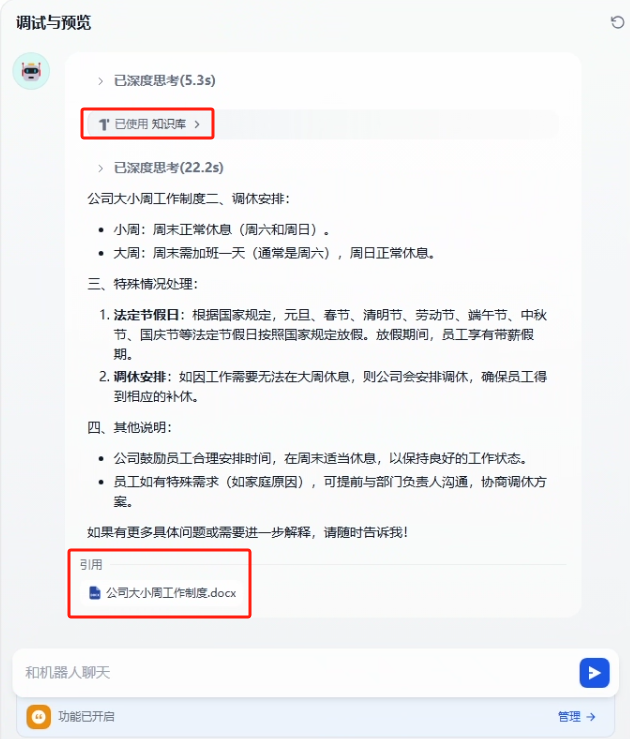
测试结果
备份与加载 RAGFlow 的镜像
一、备份 RAGFlow 的镜像
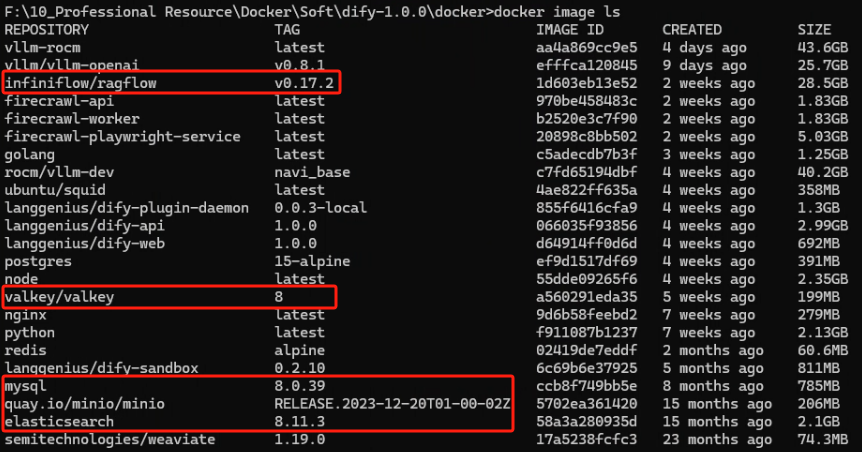
1、RAGFlow 需要备份的镜像有:infiniflow/ragflow、valkey/valkey、mysql、quay.io/minio/minio、elasticsearch,我们可以使用以下命令来查看
docker image ls
<p>bash
2、使用下面的命令来进行备份
<p>docker save -o "F:\10_Professional Resource\Docker\Images\ragflow-0.17.2_images\elasticsearch_8.11.3.tar" elasticsearch</p>
<p>docker save -o "F:\10_Professional Resource\Docker\Images\ragflow-0.17.2_images\infiniflow_ragflow_v0.17.2-full.tar" infiniflow/ragflow</p>
<p>docker save -o "F:\10_Professional Resource\Docker\Images\ragflow-0.17.2_images\mysql_8.0.39.tar" mysql</p>
<p>docker save -o "F:\10_Professional Resource\Docker\Images\ragflow-0.17.2_images\quay.io_minio_minio_RELEASE.2023-12-20T01-00-02Z.tar" quay.io/minio/minio</p>
<p>docker save -o "F:\10_Professional Resource\Docker\Images\ragflow-0.17.2_images\valkey_valkey_8.tar" valkey/valkey</p>
<p>bash

备份好的镜像:https://pan.baidu.com/s/1jx_5LbYzBsvrUve4o0MQHQ?pwd=mztx 提取码:mztx
二、加载 RAGFlow 的镜像
将备份的镜像拷贝到需要部署的机器之后使用以下命令进行镜像的载入
<p>docker load -i "F:\10_Professional Resource\Docker\Images\ragflow-0.17.2_images\elasticsearch_8.11.3.tar"</p>
<p>docker load -i "F:\10_Professional Resource\Docker\Images\ragflow-0.17.2_images\infiniflow_ragflow_v0.17.2-full.tar"</p>
<p>docker load -i "F:\10_Professional Resource\Docker\Images\ragflow-0.17.2_images\mysql_8.0.39.tar"</p>
<p>docker load -i "F:\10_Professional Resource\Docker\Images\ragflow-0.17.2_images\quay.io_minio_minio_RELEASE.2023-12-20T01-00-02Z.tar"</p>
<p>docker load -i "F:\10_Professional Resource\Docker\Images\ragflow-0.17.2_images\valkey_valkey_8.tar"</p>
<p>bash
加载完成后可以使用以下命令查看是否加载成功
docker image ls
<p>bash
当然也是需要重新下载源码以及修改环境变量和配置文件的,请重复前面 RAGFlow 部署第二步的第五点,在一切处理完成后就可以使用以下命令来启动了
<h1 id="在 RAGFlow 源码的 docker 目录下执行">在 RAGFlow 源码的 docker 目录下执行</h1>
<p>docker compose up -d</p>
<p>bash
