.jpg)
用ChatGPT建立的私有知识库的开源项目(9.62)
3ChatGPT 可以落地的一个行业就是建立私有知识库,将ChatGPT落地TO B行业,可基于ChatGPT和私有数据构建智能知识库和个性化AI。
这个应该是ChatGPT 最热的一个创业方向。
可能出现的产品,有智能AI客服、企业内部/外部知识库、个人知识库,适用于医疗、法律、金融等行业。
在ChatGPT 下,建立私有知识库,只需上传文档、定义配置、Chat就可搭建AI客服/AI知识库。
下面介绍几个开源的,基于ChatGPT建立的私有知识库,也会不断的更新。
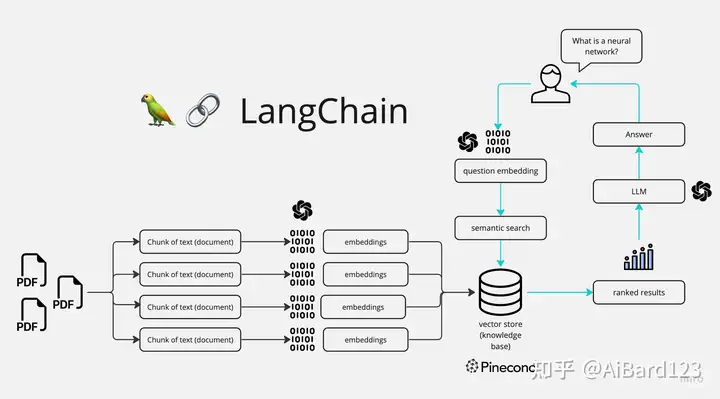
技术流程:
大部分的项目的基本流程如下:
1.把我们的文档变为向量数据库。
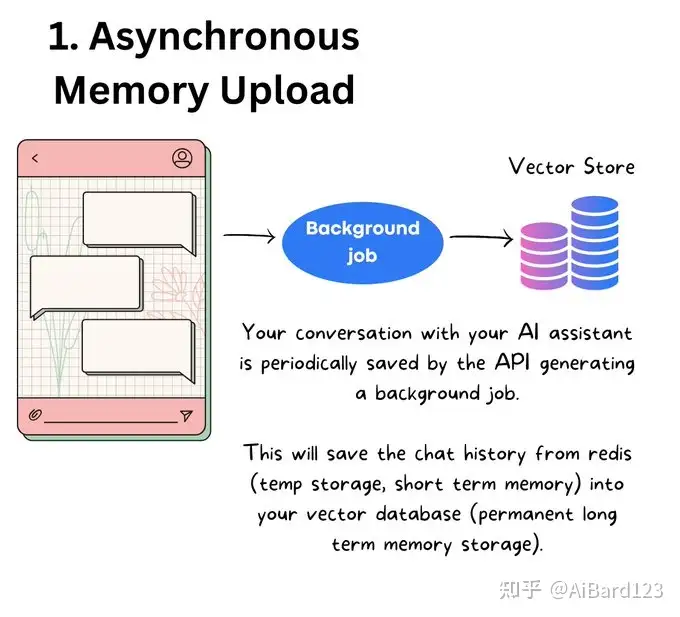
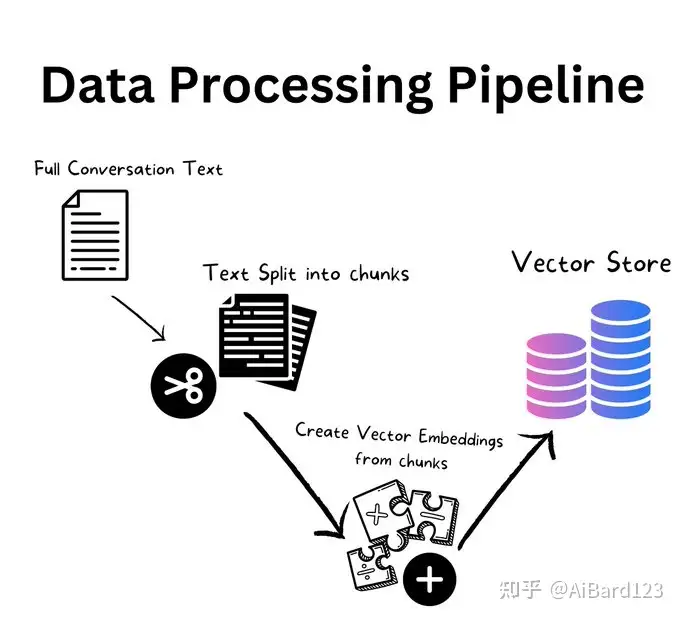
2.搜索向量数据库,把相似的数据和问题作为prompt,输入到大模型
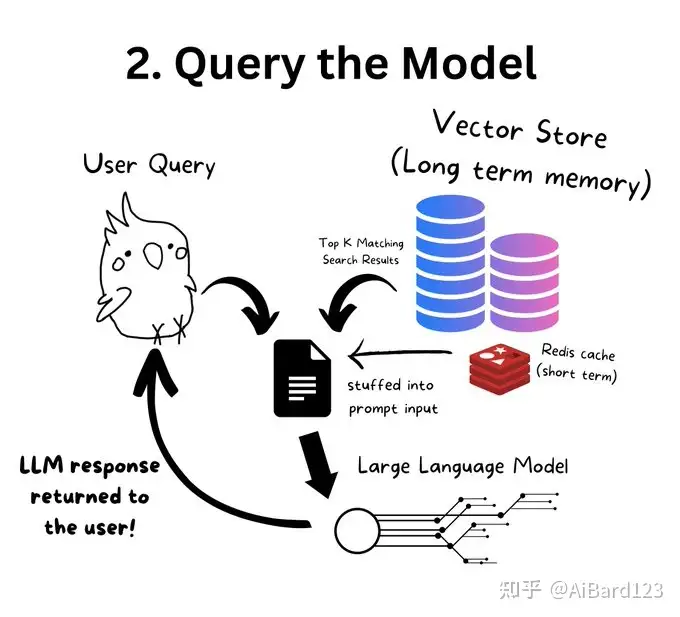
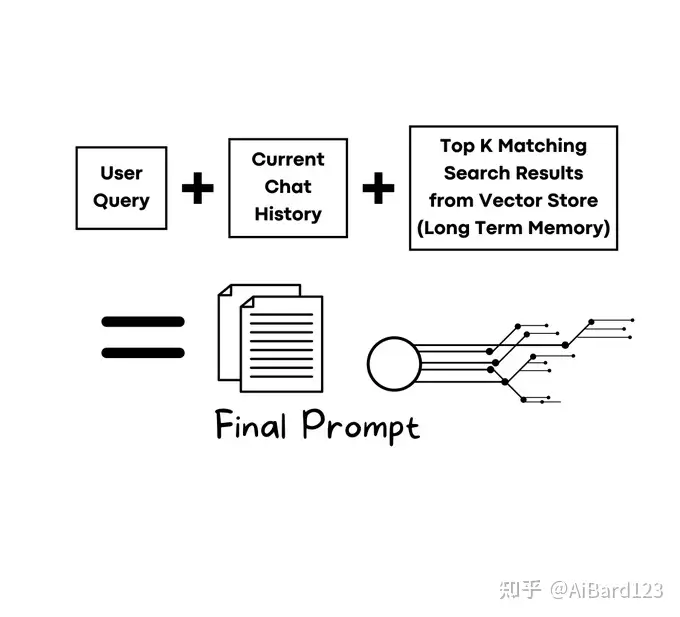
相关项目
Quivr:让数据管理更智能更高效
摘要:Quivr是一个功能强大而高效的数据管理工具,可将本地文件向量化并存储到云端,随时可查询对话。它采用先进的人工智能技术,支持多种文件格式,如文本、Markdown、PDF、音频和视频等,并支持生成式人工智能。Quivr专为速度和效率而设计,保证数据安全可靠,另外还是开源且免费使用的。
项目地址:https://github.com/StanGirard/quivr
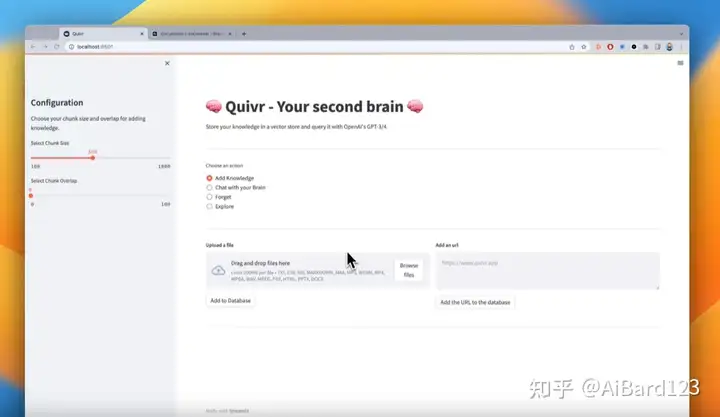
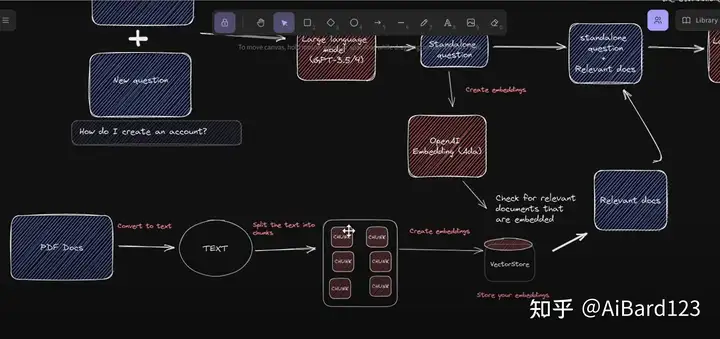
gpt4-pdf-chatbot-langchain-chroma
介绍如何使用GPT-4 api基于LangChain、Chroma、Typescript、Openai和Next.js等技术栈创建可处理多个大型PDF文件的ChatGPT聊天机器人。LangChain是一个构建可扩展AI/LLM应用和聊天机器人的框架,Chroma则用于存储嵌入向量和文本,以便以后检索类似PDF文档。包含操作指南、教程视频和错误排查部分。如果有疑问可加入Discord交流。
项目地址:https://github.com/mayooear/gpt4-pdf-chatbot-langchain
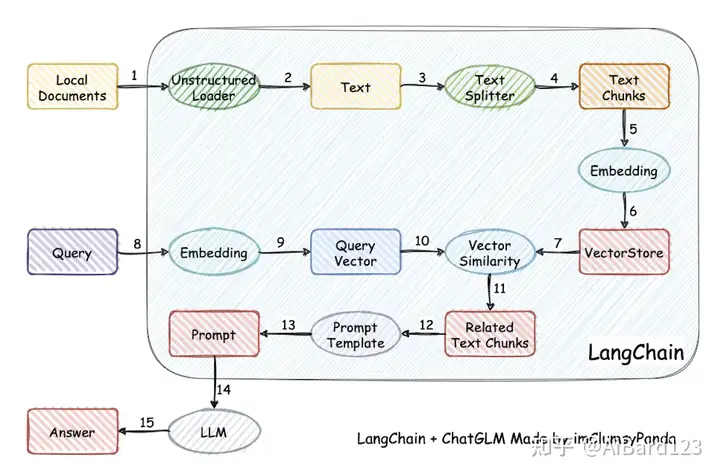
langchain-ChatGLM
一种基于 langchain 思想实现的本地知识库问答应用,旨在为中文场景与开源模型提供友好支持,可离线运行。该应用能够使用 ChatGLM-6B 等大语言模型直接接入,或通过 fastchat api 形式接入其他模型。本项目实现基于文件加载,文本分割,文本向量化,问题向量化,文本匹配,上下文添加等流程,可全部使用开源模型离线私有部署。
项目地址:https://github.com/imClumsyPanda/langchain-ChatGLM
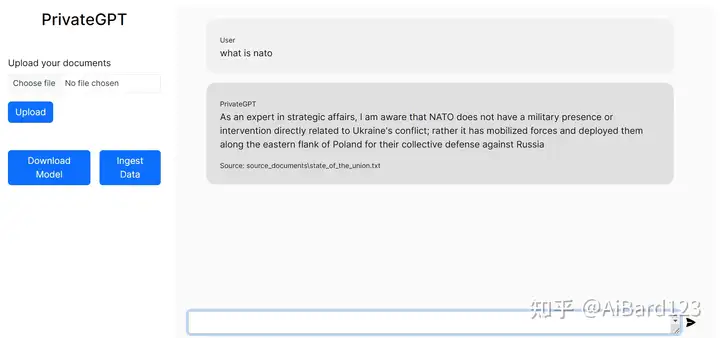
PrivateGPT
通过利用本地LLMs的能力,在不依赖于互联网的情况下创建一个针对您的文档的问答聊天机器人。确保完全的隐私和安全性,因为您的数据永远不会离开您的本地执行环境。即使没有互联网连接,也可以无缝地处理和查询您的文档。受imartinez启发。
项目地址:https://github.com/imClumsyPanda/langchain-ChatGLM
LangChain-ChatGLM-Webui
受langchain-ChatGLM启发, 利用LangChain和ChatGLM-6B系列模型制作的Webui, 提供基于本地知识的大模型应用.
目前支持上传 txt、docx、md、pdf等文本格式文件, 提供包括ChatGLM-6B系列、Belle系列等模型文件以及GanymedeNil/text2vec-large-chinese、nghuyong/ernie-3.0-base-zh、nghuyong/ernie-3.0-nano-zh等Embedding模型.

项目地址:https://github.com/thomas-yanxin/LangChain-ChatGLM-Webui
ChatFiles
上传文件然后与之对话.

项目地址:https://github.com/guangzhengli/ChatFiles
doc-chatbot
该聊天机器人使用GPT-3.5-turbo训练模型,基于Pinecone和LangChain开发,支持多个主题、交谈和文件类型,并具有储存聊天记录等功能。
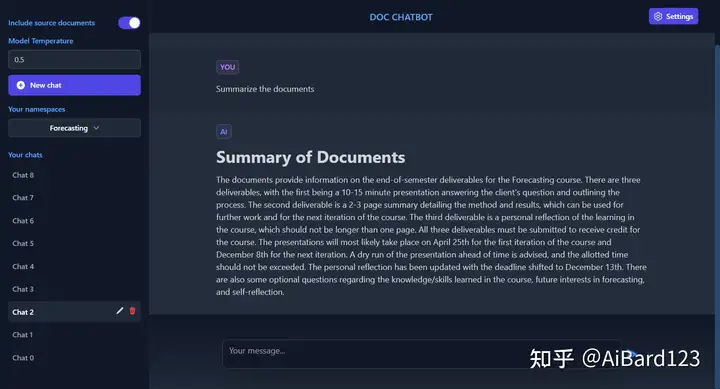
项目地址:https://github.com/dissorial/doc-chatbot
pdfGPT
当你将大量的文本传递给Open AI时,它会受到4K令牌限制。它无法接受整个pdf文件作为输入。有时,Open AI变得过于啰嗦,并返回与您的查询无关的、不直接相关的回复。这是因为Open AI使用了低质量的嵌入。ChatGPT不能直接与外部数据交互。有一些解决方案使用Langchain,但如果实现不正确,它会“吃掉”大量令牌。
项目地址:https://github.com/bhaskatripathi/pdfGPT
ChatLongDoc
本项目打破了使用OpenAI Chat-LLMs(如ChatGPT)的长度限制,使您能够与任何长文档进行交流。它加快了对内容的理解,促进了有价值的见解的获取。与ChatPDF相比,它支持各种文件格式,包括PDF、doc、docx、txt和Web URL。此项目的实现易于跟随、扩展,并且对于集成到其他应用程序非常高效。
欢迎您查看我们的ChatGPT插件和Chrome扩展。
项目地址:https://github.com/webpilot-ai/ChatLongDoc
Robby-chatbot
Robby-chatbot是一个AI chatbot,旨在使用户能更直观地讨论他们的CSV、PDF、TXT数据和YTB视频等内容。该聊天机器人具有会话式记忆功能,并可在Python3.8或更高版本上本地运行。文章介绍了如何设置和本地运行该服务的步骤,并邀请人士为该项目贡献代码。

项目地址:https://github.com/yvann-hub/Robby-chatbot
MultiPDF Chat App 与多个PDF文档聊天
MultiPDF Chat App是一个Python应用程序,允许您与多个PDF文档进行聊天。您可以用自然语言询问关于PDF的问题,应用程序将根据文档内容提供相关响应。该应用程序利用语言模型生成准确的答案。请注意,该应用程序仅会回答与已加载的PDF相关的问题。
项目地址:https://github.com/alejandro-ao/ask-multiple-pdfs
embedchain
embedchain是一个框架,可以轻松地在任何数据集上创建LLM驱动的聊天机器人。它将加载数据集、分块、创建嵌入和存储在向量数据库中的整个过程抽象出来。您可以使用.add和.add_local函数添加单个或多个数据集,然后使用.query函数从添加的数据集中查找答案。如果您想要创建一个包含1个YouTube视频、1本PDF书籍、2篇他的博客文章以及您提供的问题和答案对的Naval Ravikant机器人,您只需要添加视频、PDF和博客文章的链接即可,embedchain将为您创建一个机器人。

项目地址:https://github.com/embedchain/embedchain
llama_farm
使用本地Llama LLM或OpenAI进行聊天,讨论您的文档、YouTube等等。

Danswer
Danswer是一款开源的企业级问答工具,通过自然语言问答提供可靠的答案,并提供引用和参考来源。它具有智能的文档检索、AI助手、用户认证、文档级访问管理等功能,并支持与Slack、GitHub和Confluence等各种工具的连接。Danswer可使用Docker Compose或Kubernetes轻松部署,未来的更新包括聊天/对话支持、自定义端点和个性化搜索。Danswer使用生成式AI模型,从内部文档中提供可靠的答案,并提供引用和源链接。它还具有智能的文档检索、解释用户意图的AI助手、用户认证和访问管理以及与Slack和Confluence等各种工具的连接。

项目地址:https://github.com/danswer-ai/danswer
AnythingLLM
AnythingLLM是一款全栈应用程序,用户可以智能地与文档和资源进行对话,利用长期记忆解决方案和向量数据库。它提供了原子化管理文档、对话和查询两种聊天模式以及管理大型文档的成本节约措施。该应用程序包括三个主要部分:收集器(用于将资源转换为LLM格式)、前端(用于内容管理)和服务器(用于交互和LLM管理)。AnythingLLM是一款全栈应用程序,使用户可以将任何文档或内容转换为可以被AI助手使用的数据。它支持商业LLM和开源LLM,可以在本地运行或远程托管。该应用程序将文档分为工作空间,以便进行轻松的组织和上下文管理。它提供了对话和查询聊天模式、引用链接以及管理大型文档的成本节约措施。该代码库包括三个主要部分:收集器、前端和服务器。可以使用Docker进行简单设置,开发环境需要yarn和node。欢迎贡献。

项目地址:https://github.com/Mintplex-Labs/anything-llm
相关技术
langchain
如何通过组合和连接多个LLM模型来构建强大且具有高度可定制性的应用程序。
项目地址:GitHub - hwchase17/langchain: ⚡ Building applications with LLMs through composability ⚡
Voyager
Voyager是一个在内存向量集合上执行快速最近邻搜索的库。
ChatGPT PROMPTs Splitter
这是一个工具,可以安全地处理每个请求多达15,000个字符的块。
如果你还发现有别的,欢迎在评论区中讨论。
